penetration testing
cybersecurity
red team
What is a buffer overflow and how to exploit this vulnerability
What is buffer overflow?
Buffers are regions of memory storage that temporarily hold data as it is transferred from one location to another. A buffer overflow (or buffer underflow) occurs when the volume of data exceeds the storage capacity of the memory buffer. As a result, the program attempting to write data to the buffer overwrites adjacent memory locations.
For example, a buffer for login credentials can be designed to expect 8-byte username and password entries, so that if a transaction involves a 10-byte entry (i.e., 2 bytes more than expected), the program can write the excess. data beyond the buffer limit.
Buffer overflows can affect all types of software. They are usually the result of incorrectly formatted entries or not allocating enough buffer space. If the transaction overwrites executable code, it can cause the program to behave unpredictably and generate incorrect results, memory access errors, or crashes.
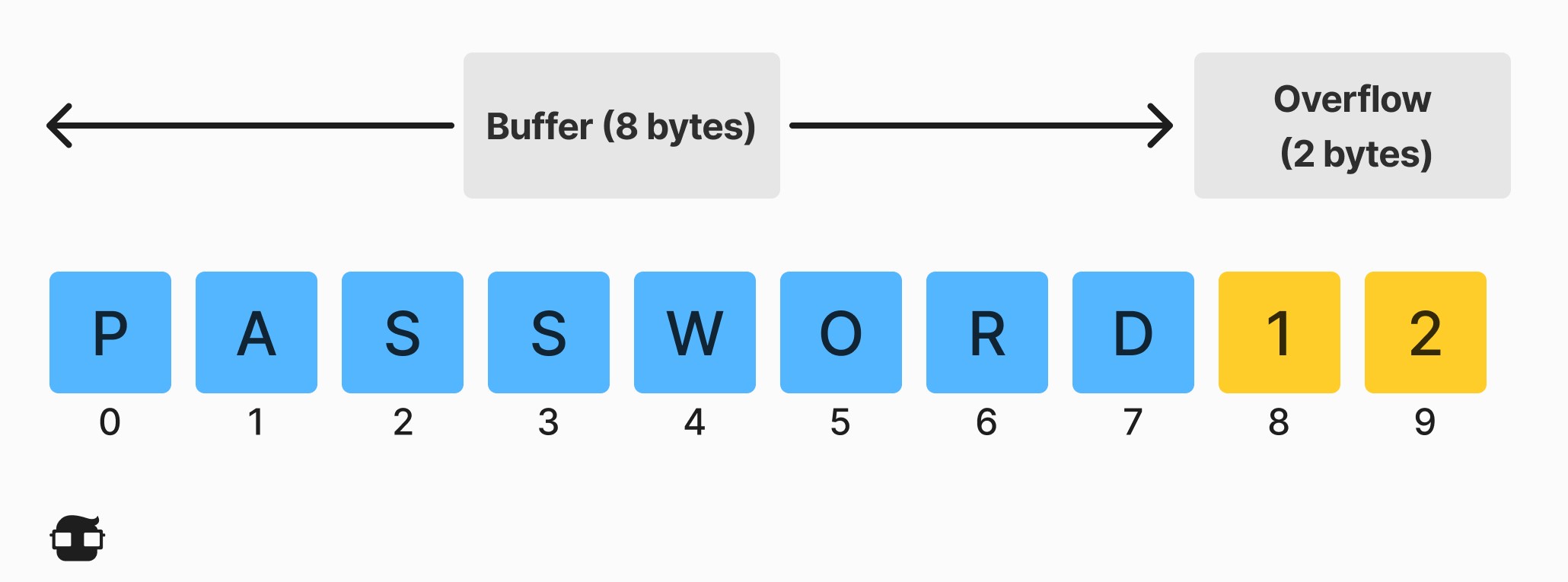
A buffer overflow occurs when a program attempts to write too much data to the buffer. This can cause the program to crash or execute arbitrary code. Buffer overflow vulnerabilities exist only in low-level programming languages such as C with direct memory access. However, they also affect users of high-level web languages because frameworks are often written in low-level languages. The following is the source code of a C program that has a buffer overflow vulnerability:
1char greeting[5]; 2 3memcpy(greeting, "Hello, world!\n", 15); 4 5printf(greeting);
What do you think will happen when we compile and run this vulnerable program? The answer may be surprising: anything can happen. When this code fragment is executed, it will attempt to place fifteen bytes into a destination buffer that is only five bytes long. This means that ten bytes will be written to memory addresses outside the array. What happens next depends on the original contents of the overwritten ten bytes of memory.
Perhaps important variables were stored there and we just changed their values? The above example is broken in such an obvious way that no sane programmer would make such a mistake. So let's consider another example. Suppose we need to read an IP address from a file. We can do this using the following C code:
1#include <stdio.h> 2 3#define MAX_IP_LENGTH 15 4 5int main(void) { 6 char file_name[] = "ip.txt"; 7 FILE *fp; 8 fp = fopen(file_name, "r"); 9 10 char ch; 11 int counter = 0; 12 char buf[MAX_IP_LENGTH]; 13 14 while ((ch = fgetc(fp)) != EOF) { 15 buf[counter++] = ch; 16 } 17 18 buf[counter] = '\0'; 19 printf("%s\n", buf); 20 fclose(fp); 21 return 0; 22}
The error in the above example is not so obvious. We assume that the IP address we want to read from a file will never exceed 15 bytes. Proper IP addresses (e.g. 255.255.255.255.255) cannot be longer than 15 bytes. However, a malicious user can prepare a file containing a very long fake string instead of an IP address (e.g. 19222222222.16888888.0.1). This string will cause our program to overflow the destination buffer.
What is a buffer overflow attack?
Attackers exploit buffer overflow problems by overwriting an application's memory. This changes the program's execution path, triggering a response that damages files or exposes private information. For example, an attacker can enter additional code and send new instructions to the application to gain access to IT systems.
If attackers know the memory layout of a program, they can intentionally feed entries that the buffer cannot store and overwrite areas containing executable code, replacing it with their own code. For example, an attacker can overwrite a pointer (an object that points to another area of memory) and point it to an exploit payload to gain control over the program.
- Example of Stack Buffer Overflow Attack.
Now that we know that a program can overflow an array and overwrite a piece of memory that it should not overwrite, let's see how this can be used to mount a buffer overflow attack. In a typical scenario (called a stack buffer overflow), the problem is due (like so many problems in information security) to the mixing of data (intended to be processed or displayed) with commands that control program execution. In C, as in most programming languages, programs are created using functions.
Functions call each other, pass arguments to each other, and return values. For example, our code, which reads an IP address from a file, could be part of a function called readIpAddress, which reads an IP address from a file and parses it. This function could be called by some other function, for example, readConfiguration. When readConfiguration calls readIpAddress, it passes a file name and then the readIpAddress function returns an IP address as a four-byte array. The arguments and return value of the readIpAddress function.
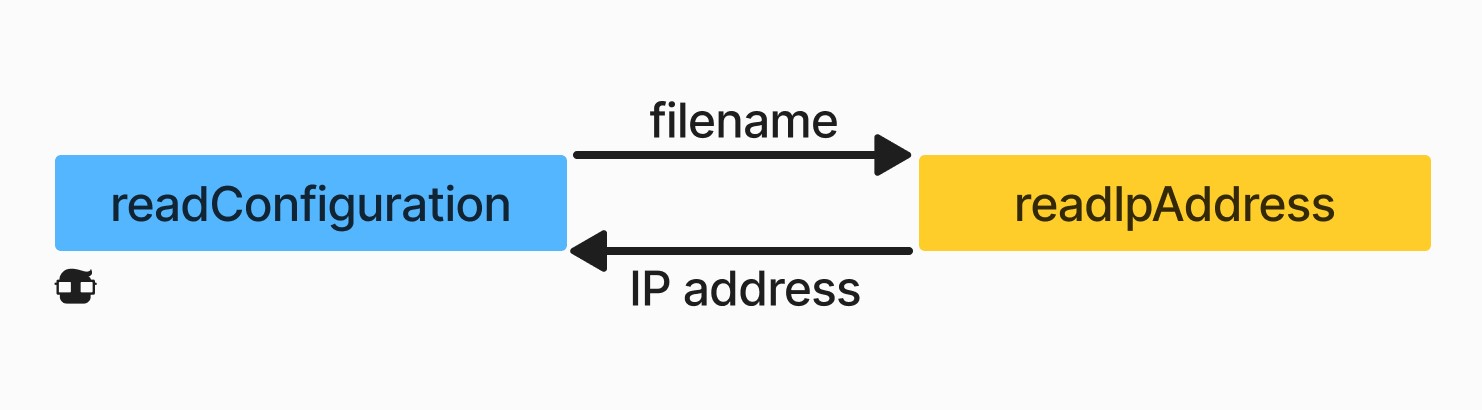
During this function call, three different pieces of information are stored side by side in the computer's memory. For each program, the operating system maintains a region of memory that includes a part called stack or call stack (hence the name stack buffer overflow). When a function is called, it is allocated a piece of the stack. This piece of the stack (called frame) is used to:
- Remember the line of code from which to resume program execution when function execution completes (in our case, it will be a specific line of the readConfigurationfunction).
- Store the arguments passed to the function by its caller (in our case, let's assume /home/someuser/myconfiguration/ip.txt).
- Store the return value that the function returns to its caller (in our case, it is an array of four bytes, say (192, 168, 0, 1)).
- Store local variables of the called function while executing this function (in our case, the variable char[MAX_IP_LENGTH] buf).
👉 So, if a program has a buffer allocated in the stack frame and attempts to insert more data than will fit there, the user-entered data may overflow and overwrite the memory location where the sender address is stored. Contents of the stack frame when the readIPAddress function is called:
 .
.
If the problem was caused by ill-formed random input data from the user, the new return address most likely does not point to a memory location where any other program is stored, so the original program will simply fail. However, if the data is carefully prepared, it can lead to unwanted code execution.
The first step for the attacker is to prepare special data that can be interpreted as executable code and work to the attacker's advantage (this is called shell code). The second step is to place the address of this malicious data in the exact location where the sender's address should be. The contents of ip.txt overwrites the sender's address:

When the function reads the IP string and places it in the destination buffer, the return address is replaced by the address of the malicious code. When the function terminates, program execution jumps to the malicious code.
Types of buffer overflow attacks
Stack-based buffer overflows are more common and exploit heap memory that only exists during the execution time of a function.
Heap-based attacks are more difficult to perform and involve flooding the memory space allocated for a program beyond the memory used for current runtime operations.
Which programming languages are most vulnerable?
C and C++ are two languages that are very susceptible to buffer overflow attacks, as they have no built-in protections against overwriting or accessing data in their memory. Mac OSX, Windows, and Linux use code written in C and C++.
Languages such as PERL, Java, JavaScript, and C# use built-in security mechanisms that minimize the likelihood of buffer overflows.
How to prevent buffer overflows
Developers can protect against buffer overflow vulnerabilities by security measures in their code or by using languages that offer built-in protection.
In addition, modern operating systems have runtime protection. Three common protections are:
- Address space randomization (ASLR): randomly moves through the address space locations of data regions. Normally, buffer overflow attacks need to know the locality of executable code, and address space randomization makes this virtually impossible.
- Data execution prevention: marks certain areas of memory as non-executable or executable, which prevents an attack from executing code in a non-executable region.
- Structured Exception Handler Overwrite Protection (SEHOP): Helps prevent malicious code from attacking Structured Exception Handling (SEH), an integrated system for managing hardware and software exceptions. It thus prevents an attacker from being able to make use of the SEH overwrite exploitation technique. At a functional level, a SEH overwrite is achieved by using a stack-based buffer overflow to overwrite an exception log record, stored on the stack of a thread.
Keep up to date with the latest bug reports for your web and application server products and other products in your Internet infrastructure. Apply the latest patches to these products. Periodically scan your website with one or more of the commonly available scanners that look for buffer overflow flaws in your server products and your custom web applications.
For your custom application code, you should review all code that accepts input from users via HTTP request and ensure that you provide a proper size check on all such input. This should be done even in environments that are not susceptible to this type of attack, as oversized inputs that are not yet detected can cause denial of service or other operational problems.
Security measures in code and operating system protection are not enough. When an organization discovers a buffer overflow vulnerability, it must react quickly to patch the affected software and ensure that users of the software can access the patch.
Programmers can mitigate the risk of buffer overflow attacks by always validating the length of user input. However, a good general way to avoid buffer overflow vulnerabilities is to continue to use safe functions that include buffer overflow protection (which memcpy does not). These functions are available on different platforms, e.g. strlcpy, strlcat, snprintf(OpenBSD) or strcpy_s, strcat_s, sprintf_s(Windows).
Categorization of NVD
CWE-788: Access to memory location after end of buffer: this usually occurs when a pointer or its index is incremented to a location after the buffer; or when pointer arithmetic results in a location after the buffer.
Buffer overflow is probably the best-known form of software security vulnerability. Most software developers know what a buffer overflow vulnerability is, but buffer overflow attacks against legacy and newly developed applications are still quite common. Part of the problem is due to the wide variety of ways buffer overflows can occur, and part is due to the error-prone techniques that are often used to avoid them.
Buffer overflows are not easy to discover and even when one is discovered, it is usually extremely difficult to exploit. However, attackers have managed to identify buffer overflows in a staggering variety of products and components.
In a classic buffer overflow exploit, the attacker sends data to a program, which stores it in a stack buffer of insufficient size. The result is that the call stack data, including the function return pointer, is overwritten. The data sets the value of the return pointer so that when the function returns, it transfers control to the malicious code contained in the attacker's data.
While this type of stack buffer overflow is still common on some platforms and in some development communities, there are a variety of other types of buffer overflows, including heap buffer overflow and one-by-one error, among others. Another very similar kind of failure is known as format string attack. Several excellent books provide detailed information on how buffer overflow attacks work, including Building Secure Software, Writing Secure Code, and The Shellcoder's Handbook.
At the code level, buffer overflow vulnerabilities generally involve violating programmer assumptions. Many memory manipulation functions in C and C++ do not perform bounds checking and can easily overwrite the allocated bounds of the buffers they operate on. Even bounded functions, such as strncpy(), can cause vulnerabilities when used incorrectly. The combination of memory manipulation and erroneous assumptions about the size or composition of a piece of data is the root cause of most buffer overflows.
Buffer overflow vulnerabilities typically occur in code that:
- Relies on external data to control its behavior.
- Depends on data properties that apply outside the immediate scope of the code.
- Is so complex that a programmer cannot accurately predict its behavior.
Since the discovery of the stack buffer overflow attack technique, authors of operating systems (Linux, Microsoft Windows, macOS, and others) have tried to find prevention techniques:
- The stack can be made non-executable, so even if malicious code is placed in the buffer, it cannot be executed.
- The operating system can randomize the memory layout of the address space (memory space). When malicious code is placed in a buffer, the attacker cannot predict its address.
- Other protection techniques (e.g. StackGuard) modify a compiler in such a way that each function calls a piece of code that ensures that the sender's address has not changed.
In practice, even if such protection mechanisms make stack buffer overflow attacks more difficult, they do not make them impossible. Some of these measures can also affect performance. Buffer overflow vulnerabilities exist in programming languages that, like C, trade security for efficiency and do not check memory access. In higher-level programming languages (e.g., Python, Java, PHP, JavaScript, or Perl), which are often used to create web applications, buffer overflow vulnerabilities cannot exist. In these languages, you simply cannot place excess data in the target buffer. For example, try compiling and executing the following Java code:
1int[] buffer = new int[5]; 2 3buffer[100] = 44;
The Java compiler will not warn you, but the Java virtual machine at runtime will detect the problem and, instead of overwriting random memory, will interrupt the execution of the program.
Buffer overflows and web applications
Attackers use buffer overflows to corrupt the execution stack of a web application. By sending carefully crafted information to a web application, an attacker can cause the web application to execute arbitrary code, effectively taking over the machine.
Buffer overflow flaws can be present in both the web server and the application server products that service the static and dynamic aspects of the site, or in the web application itself. Buffer overflows found in widely used server products are likely to become widely known and may pose a significant risk to users of these products. When web applications use libraries, such as a graphics library to generate images, they are exposed to potential buffer overflow attacks.
Buffer overflows can also be found in custom web application code, and may even be more likely given the lack of scrutiny that web applications typically go through. Buffer overflow flaws are less likely to be detected in custom web applications because there will typically be far fewer hackers attempting to find and exploit such flaws in a specific application. If discovered in a custom application, the ability to exploit the flaw (other than crashing the application) is significantly reduced by the fact that the source code and detailed error messages for the application are usually not available to the hacker.
However, even programmers using high-level languages should be aware of and concerned about buffer overflow attacks. Their programs often run inside operating systems written in C or use runtime environments written in C, and this C code can be vulnerable to such attacks.
To see how a buffer overflow vulnerability can affect a programmer using such a high-level programming language, let's look at CVE-2015-3329, a real-life security vulnerability discovered in the PHP standard library in 2015. A PHP application is a collection of *.php files. To facilitate the distribution of such an application, it can be packaged into a single archive, such as a zip archive, a tar archive, or a custom PHP format called phar.
A PHP extension called phar contains a class that you can use to work with such archives. With this class, you can parse an archive, enumerate its archives, extract them, and so on. Using this class is quite simple. For example, to extract all files from an archive, use the following code:
1$phar = new Phar('phar-file.phar'); 2 3$phar->extractTo('./directory');
When the Phar class parses a file (i.e. new Phar('phar-file.phar'), it reads all the filenames in the file, concatenates each filename with the file name, and then calculates the checksum. For example, for a file named myarchive.phar containing index.php and components/hello.php files, the Phar class calculates checksums of two strings: myarchive.pharindex.php and myarchive.pharcomponents/hello.php.
Why the authors implemented it this way is not important here; what is important is how they implemented it. Until 2015, this operation was performed by the following function (see old PHP source code):
1void phar_set_inode(phar_entry_info *entry TSRMLS_DC) 2{ 3 char tmp[MAXPATHLEN]; 4 int tmp_len; 5 6 tmp_len = entry->filename_len + entry->phar->fname_len; 7 8 memcpy(tmp, entry->phar->fname, entry->phar->fname_len); 9 memcpy(tmp + entry->phar->fname_len, entry->filename, entry->filename_len); 10 11 entry->inode = (unsigned short)zend_get_hash_value(tmp, tmp_len); 12}
As you can see, this function creates a char array named tmp. First, the name of the phar archive (in our example, myarchive.phar ) is copied into this array using the following command:
1memcpy(tmp,entry->phar->fname,entry->phar->fname_len);
In this command:
- The first argument, tmpes a destination where the bytes are to be copied.
- The second argument, entry->phar->fname, is a source from which the bytes should be copied; in our case, the name of the file ( myarchive.phar ).
- The third argument, entry->phar->fname_lenes a number of bytes to be copied; in our case, it is the length (in bytes) of the archive name.
The function copies the file name (in our example, index.php or components/hello.php ) into the character tmpmatrix using the following command:
1memcpy(tmp + entry->phar->fname_len, entry->filename, entry->filename_len);
In this command:
- The first argument, tmp + entry->phar->fname_lenes a destination where the bytes should be copied to; in our case, it is a location in the tmpmatrix just after the end of the filename.
- The second argument, entry->filename is a source from which the bytes should be copied.
- The third argument, entry->filename_lenes a number of bytes to be copied.
Then zend_get_hash_valuese calls the function to calculate the hash code. Note how the buffer size is declared:
char tmp[MAXPATHLEN];
It has a size of MAXPATHLEN, which is a constant defined as the maximum length of a file system path on the current platform. The authors assumed that if you concatenate the file name with the name of a file within the file, you will never exceed the maximum allowable path length. In normal situations, this assumption holds. However, if the attacker prepares a file with unusually long names, a buffer overflow is imminent.
The phar_set_inode function will cause an overflow in the tmp array. An attacker can use this to crash PHP (causing a denial of service) or even make it execute malicious code. The problem is similar to our simple example above: the programmer made a simple mistake, relied too much on user input, and assumed that the data would always fit in a fixed-size buffer. Fortunately, this vulnerability was discovered in 2015 and fixed.
Consequences
- Category: Availability: buffer overflows generally cause failures. Other attacks causing unavailability are possible, including putting the program in an infinite loop.
- Access control (instruction processing): buffer overflows can often be used to execute arbitrary code, which is generally outside the scope of a program's implicit security policy.
- Other: when the consequence is arbitrary code execution, this can often be used to subvert any other security services.
Exposure period
- Requirements specification: One could choose to use a language that is not susceptible to these problems.
- Design: Mitigation technologies such as safe string libraries and container abstractions could be introduced.
- Implementation: Many logical errors can cause this condition. It can be exacerbated by the lack or misuse of mitigation technologies.
Affected environments
Almost all known web servers, application servers, and web application environments are susceptible to buffer overflows, with the notable exception of environments written in interpreted languages such as Java or Python, which are immune to these attacks (except for overflows in the Interpreter itself).
Platform
- Languages: C, C++, Fortran, Assembler
- Operating Platforms: All, although partial preventative measures may be implemented, depending on the environment.
How to determine if you are vulnerable
For server products and libraries, keep up to date with the latest bug reports for the products you are using. For custom application software, all code that accepts input from users via HTTP request should be reviewed to ensure that it can properly handle arbitrarily large input.
- Example 1
The following example code demonstrates a simple buffer overflow that is often caused by the first scenario in which the code relies on external data to control its behavior. The code uses the get() function to read an arbitrary amount of data into a stack buffer. Because there is no way to limit the amount of data read by this function, the safety of the code depends on the user always entering fewer than BUFSIZE characters.
1... 2 3char buf[BUFSIZE]; 4 5gets(buf); 6 7...
This example shows how easy it is to mimic the unsafe behavior of the gets() function in C++ by using the >> operator to read the input in a char[] string.
1... 2 3char buf[BUFSIZE]; 4 5cin >> (buf); 6 7...
- Example 2
The code in this example also relies on user input to control its behavior, but adds a level of indirect addressing with the use of the memcpy() limited memory copy function. This function accepts a destination buffer, a source buffer, and the number of bytes to copy. The input buffer is filled by a limited call to read(), but the user specifies the number of bytes that memcpy() copies.
1... 2 3char buf[64], in[MAX_SIZE]; 4 5printf("Enter buffer contents:\n"); 6 7read(0, in, MAX_SIZE - 1); 8 9printf("Bytes to copy:\n"); 10 11scanf("%d", &bytes); 12 13memcpy(buf, in, bytes); 14 15...
Note: This type of buffer overflow vulnerability (where a program reads data and then relies on a value of the data in subsequent memory operations on the remaining data) has appeared with some frequency in image, audio, and other file processing libraries.
- Example 3
This is an example of the second scenario in which the code relies on data properties that are not verified locally. In this example, a function named lccopy() takes a string as an argument and returns a copy of the string assigned to the heap with all uppercase letters converted to lowercase. The function performs an unbounded check on its input because it expects str to always be less than BUFSIZE. If an attacker bypasses the checks in the code calling lccopy(), or if a change in that code assumes the size of str false, then lccopy() will overflow with the unbounded call to strcpy().
1char *lccopy(const char *str) { 2 char buf[BUFSIZE]; 3 char *p; 4 5 strcpy(buf, str); 6 7 for (p = buf; *p; p++) { 8 if (isupper(*p)) { 9 *p = tolower(*p); 10 } 11 } 12 13 return strdup(buf); 14}
- Example 4
The following code demonstrates the third scenario in which the code is so complex that its behavior cannot be easily predicted. This code comes from the popular libPNG image decoder, which is used by a wide range of applications, including Mozilla and some versions of Internet Explorer.
The code appears to perform the bounds checking safely because it checks the size of the variable length, which it then uses to control the amount of data copied by png_crc_read(). However, immediately before testing the length, the code performs a png_ptr->modey check; if this check fails, a warning is issued and processing continues. Because the length is tested in an else if block, the length will not be tested if the first check fails and is blindly used in the call to png_crc_read(), potentially allowing a stack buffer overflow.
Although the code in this example is not the most complex we have seen, it demonstrates why complexity should be minimized in code that performs memory operations.
1if (!(png_ptr->mode & PNG_HAVE_PLTE)) { 2 /* Should be an error, but we can cope with it */ 3 png_warning(png_ptr, "Missing PLTE before tRNS"); 4} else if (length > (png_uint_32)png_ptr->num_palette) { 5 png_warning(png_ptr, "Incorrect tRNS chunk length"); 6 png_crc_finish(png_ptr, length); 7 return; 8} 9 10... 11 12png_crc_read(png_ptr, readbuf, (png_size_t)length);
- Example 5
This example also demonstrates the third scenario in which the complexity of the program exposes it to buffer overflows. In this case, the exposure is due to the ambiguous interface of one of the functions and not to the structure of the code (as was the case in the previous example).
The getUserInfo() function takes a username specified as a multibyte string and a pointer to a structure for user information and populates the structure with information about the user. Since Windows authentication uses Unicode for usernames, the username argument is first converted from a multibyte string to a Unicode string. Then, this function incorrectly passes the size in unicodeUser bytes instead of characters.
Therefore, the call toMultiByteToWideChar() can write up to (UNLEN+1)*sizeof(WCHAR)wide characters, or (UNLEN+1)*sizeof(WCHAR)*sizeof(WCHAR)bytes, into the unicodeUser array, which has only (UNLEN+1)*sizeof(WCHAR)bytes allocated. If the username string contains more than UNLENcharacters, the call to MultiByteToWideChar() will overflow the unicodeUser buffer.
Claro, aquí tienes el fragmento de código ordenado en Markdown:
1void getUserInfo(char *username, struct _USER_INFO_2 info) { 2 3 WCHAR unicodeUser[UNLEN+1]; 4 5 MultiByteToWideChar(CP_ACP, 0, username, -1, unicodeUser, sizeof(unicodeUser)); 6 7 NetUserGetInfo(NULL, unicodeUser, 2, (LPBYTE *)&info); 8 9}
Buffer overflow attack
Buffer overflow errors are characterized by the overwriting of process memory fragments, which should never have been modified intentionally or unintentionally. Overwriting values of IP (instruction pointer), BP (base pointer), and other registers causes exceptions, segmentation failures, and other errors. Generally, these errors terminate the application execution unexpectedly. Buffer overflow errors occur when operating with char buffers.
Buffer overflows can consist of a stack overflow or heap overflow. We do not distinguish between these two in this article to avoid confusion. The following examples are written in C language under GNU/Linux system on x86 architecture.
- Example 1
1#include <stdio.h> 2 3int main(int argc, char **argv) { 4 char buf[8]; // buffer for eight characters 5 6 gets(buf); // read from stdio (sensitive function!) 7 8 printf("%s", buf); // print out data stored in buf 9 10 return 0; // 0 as return value 11}
This very simple application reads from the standard input an array of characters and copies it into the buffer of type char. The size of this buffer is eight characters. After that, the contents of the buffer are displayed and the application closes.
Compilation of the program:
1user@spin ~/inzynieria $ gcc bo-simple.c -o bo-simple 2 3/tmp/ccECXQAX.o: In function `main': 4bo-simple.c:(.text+0x17): warning: the `gets' function is dangerous and should not be used. 5 6At this stage, even the compiler suggests that the gets() function is not safe.
Example of use:
1user@spin ~/inzynieria $ ./bo-simple // program start 2 31234 // we enter "1234" string from the keyboard 4 51234 // program prints out the content of the buffer 6 7user@spin ~/inzynieria $ ./bo-simple // start 8 9123456789012 // we enter "123456789012" 10 11123456789012 // content of the buffer "buf" ?!?!!! 12 13Segmentation fault // information about memory segmentation fault
We managed (un)fortunately to execute the faulty operation of the program which caused it to exit abnormally.
Problem analysis
The program calls a function that operates on the char buffer and does not perform checks to avoid overflowing the size allocated to this buffer. As a result, it is possible to intentionally or unintentionally store more data in the buffer, which will cause an error. The following question arises: The buffer stores only eight characters, so why does the printf() function display twelve? The answer comes from the organization of the process memory. Four characters that overflowed the buffer also overwrote the value stored in one of the registers, which was necessary for the correct return of the function. The memory continuity resulted in the printing of the data stored in this area of memory.
- Example 2
1#include <stdio.h> 2#include <string.h> 3 4void doit(void) { 5 char buf[8]; 6 gets(buf); 7 printf("%s", buf); 8} 9 10int main(void) { 11 printf("So... The End...\n"); 12 doit(); 13 printf("or... maybe not?\n"); 14 return 0; 15}
This example is analogous to the first one. In addition, before and after the doit() function, we have two calls to the printf() function.
Compilation
1user@dojo-labs ~/owasp/buffer_overflow $ gcc example02.c -o example02 -ggdb
Warning:
1/tmp/cccbMjcN.o: In function `doit': 2/home/user/owasp/buffer_overflow/example02.c:8: warning: the `gets' function is dangerous and should not be used.
Usage Example
1user@dojo-labs ~/owasp/buffer_overflow $ ./example02
Output:
1So... The End... 2TEST // user data on input 3TEST // print out stored user data 4or... maybe not?
The program between the two defined printf() calls displays the contents of the buffer, which is filled with the data entered by the user.
1user@dojo-labs ~/owasp/buffer_overflow $ ./example02 2 3So... The End... 4 5TEST123456789 6 7TEST123456789 8 9Segmentation fault
Because the buffer size (char buf[8]) was defined and filled with thirteen char characters, the buffer overflowed. If our binary application is in ELF format, then we can use an objdump program to parse it and find the information needed to exploit the buffer overflow error. The output produced by objdump is shown below. From that output we can find addresses, where printf() is called (0x8048483d6 and 0x8048483e7).
1user@dojo-labs ~/owasp/buffer_overflow $ objdump -d ./example02
Output:
080483be <main>:
80483be: 8d 4c 24 04 lea 0x4(%esp),%ecx
80483c2: 83 e4 f0 and $0xfffffffff0,%esp
80483c5: ff 71 fc pushl 0xfffffffffc(%ecx)
80483c8: 55 push %ebp
80483c9: 89 e5 mov %esp,%ebp
80483cb: 51 push %ecx
80483cc: 83 ec 04 sub $0x4,%esp
80483cf: c7 04 24 bc 84 04 08 movl $0x80484bc,(%esp)
80483d6: e8 f5 f5 fe ff ff ff call 80482d0 <puts@plt>
80483db: e8 c0 f0 ff ff ff ff call 80483a0 <doit>
80483e0: c7 04 24 cd 84 04 08 movl $0x80484cd,(%esp)
80483e7: e8 e4 fe ff ff ff call 80482d0 <puts@plt>
80483ec: b8 00 00 00 00 00 00 mov $0x0,%eax
80483f1: 83 c4 04 add $0x4,%esp
80483f4: 59 pop %ecx
80483f5: 5d pop %ebp
80483f6: 8d 61 fc lea 0xfffffffffc(%ecx),%esp
80483f9: c3 ret
80483fa: 90 nop
80483fb: 90 nop
If the second call to printf() would inform the administrator about the user's logout (e.g., session closed), then we can try to skip this step and finish without the call to printf().
1user@dojo-labs ~/owasp/buffer_overflow $ perl -e 'print "A "x12 . "\xf9\x83\x04\x08"' | ./example02
Output:
So... The End...
AAAAAAAAAAAAAAAAAAu*.
Segmentation fault
The application ended its execution with a segmentation fault, but the second call to printf() was not successful. Some words of explanation:
perl -e 'print "A "x12 ."\xf9\x83\x04\x08"' - will print twelve characters "A" and then four characters, which is actually an address of the instruction we want to execute. why twelve?
18 // Size of buf (char buf[8]) 2 3+ 4 // Four additional bytes for overwriting stack stack frame pointer 4 5---- 6 712
Problem analysis:
The issue is the same as in the first example. There is no control over the size of the buffer copied into the previously declared buffer. In this example, we overwrite the EIP register with address 0x08048483f9, which is a call to ret in the last phase of program execution.
How to use buffer overflow errors in a different way?
Generally, exploitation of these errors can lead to:
- DoS application
- reordering the execution of functions
- code execution (if we can inject shellcode, described in the separate document)
How buffer overflow errors are committed?
These types of errors are very easy to make. For years, they were a programmer's nightmare. The problem lies in the native C functions, which do not care to perform proper buffer length checks. The following is the list of such functions and, if they exist, their safe equivalents:
Sure, here is the translation:
gets()->fgets()- read charactersstrcpy()->strncpy()- copy the content of the bufferstrcat()->strncat()- concatenate buffersprintf()->snprintf()- fill the buffer with data of different types(f)scanf()- read from STDINgetwd()- return to the working directoryrealpath()- return the absolute (complete) path
Use safe equivalent functions, which check buffer lengths, whenever possible. Namely:
- gets() - fgets()
- strcpy() -> strncpy()
- strcat() -> strncat()
- sprintf() -> snprintf()
Those functions that do not have safe equivalents should be rewritten by implementing safe checks. The time spent on this will benefit in the future. Remember that you have to do it only once. Use compilers, which are able to identify unsafe functions, and logical errors and check if memory is overwritten when and where it should not be.
Web application exploits: how hackers exploit buffer overflow vulnerabilities
In the Firefox web browser, search for the following URL:
This is a deliberately vulnerable web application used for educational and testing purposes. Select Login and log in to the application using the following credentials:
Username → admin
Password → admin
Click on the Feedback link next to the search bar in the upper right corner.
 .
.
The application does not perform a length check and is vulnerable to overflow attacks.
If an attacker sends more data than the buffer can hold, the excess data will overflow into adjacent memory areas, potentially overwriting critical data or application code. This can lead to unpredictable and potentially malicious behavior.
Scripting for the Red Team.
LOLBAS: a collection of scripts for Red Team attacks
Various researchers and hackers have set out to build a list of LOLBins, legitimate programs that can be abused to bypass security and evade detection. These programs can be used by Red Team teams or directly by attackers in malware, APTs, and in situations of privilege escalation and lateral attacks.
Trust is one of the key pillars on which information security is based. Ultimately, it determines who has access to what, and which applications can run and which cannot. But what happens when that trust is abused? For example, when authorized and trusted applications are used by attackers.
LOLBins are a good example of trust exploitation: they are "trusted" binaries that an attacker can use to perform actions other than those for which they were originally designed. As such, LOLBins make it possible for attackers to bypass defensive countermeasures such as application whitelisting, security monitoring, and anti-virus software with a lower chance of detection. An example, one can use the print.exe command to copy a file to an Alternate Data Stream (ADS) and then execute it.
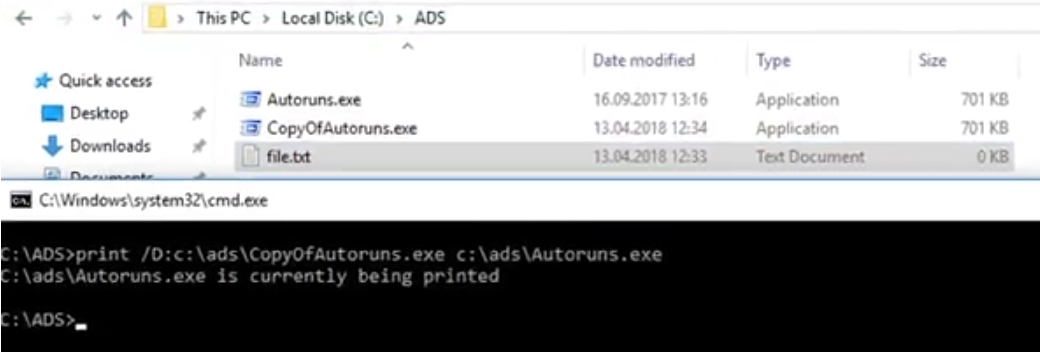
LOLBAS ("Living Off the Land Binaries and Scripts").
Currently, there are over 130 LOLBins, LOLLibs, and LOLScripts on the list, ranging from Microsoft's legitimate data transfer tool Bitsadmin.exe to print.exe. The list includes programs that have documented abuse potential, as well as a variety of programs that have already become favorite tools for retrieving malware payloads during real-world attacks, including mshta.exe, certutil.exe, and regsvr32.exe.
Having good documentation on these binaries and scripts can help everyone prevent attacks by actively blocking their execution. If you know that something can be used for evil, it makes the job much easier when looking for attacks and trying to prevent them. After all, advanced persistence threat actors (APTs)are already using these binaries/scripts as part of their attacks. Therefore, we need to dig deep into all the files and discover clever ways we can use this list before the attackers do.
LOLBAS functions as a dynamic list maintained by the community. Anyone interested in doing security research to submit new LOLBins is encouraged to do so and be recognized for it. The current list is just the beginning and it is hoped to be able to provide a searchable list in a database format for the service, map it to the MITRE ATT & CK framework, and add more data on each LOLBin and LOLScript record, including information on its detection and relevant blocking techniques.
GTFOBins
GTFOBins is a list inspired by LOBAS but with Unix/Linux binaries that can be exploited by an attacker to bypass local security restrictions.
Offensive-PowerShell
Offensive-PowerShell is a GitHub repository containing a compilation of scripts in Powershell for offensive operations related to Red Teaming tasks. They describe how each one works and give a short tutorial on how to use them, as well as saying which versions of Windows they are compatible with.
Automating Red Team Recognition with Discover Scripts
When we talk about Red Team, the scope of it not only covers technologies but also people and processes. Another thing that we have already mentioned more than once is that, unlike a traditional pentest, which is much more limited in time and scope, a red team service is much broader both in its execution time window and in its scope since, among other things, it tries to generate as many scenarios as possible or even replicate known APT campaigns, which results in a much more holistic result about the security posture of a given company or entity.
Having clarified the context, it is clear that the reconnaissance phase in the Red Team world, as opposed to a traditional pentest, is of vital importance. When we talk about reconnaissance, we are talking about OSINT in all its aspects or what is traditionally referred to as passive and active information gathering. This is because an attack scenario is usually modeled with much more time in a network team exercise.
The more time we spend on this phase, the more attack vectors that can be used to carry out a successful attack, from the AWS bucket, services that should not necessarily be exposed (RDP for example), web management panels, possible Github accounts where the company's developers store their company's code, etc. In a Red Team exercise, everything and absolutely everything that can be found can be exposed to vulnerability.
The tool is called "Discover Scripts" by Lee Baird @discoverscripts (https://github.com/leebaird/discover) and was formerly known as Backtrack Scripts, you can imagine because it was part of the Backtrack Kali Linux suite of tools before it became Kali Linux.
This tool or set of scripts, I use it a lot in particular and the interesting thing is that it can also be used for other issues not so related to OSINT but through it, you can trigger other tools such as Recon-NG or for example Nikto for a web scan.
Discover Scripts, as its name suggests, is a set of scripts that trigger actions or tools. It uses tools such as "dnsrecon, goofile, goog-mail, goohost, theharvester, metasploit, urlcrazy, whois, wikto, and several others.
Installation
To install it, just clone the repository from its official git clone site.

Once the installation is finished we should move to the /opt/discover directory which is where it is installed by default. The first thing to do now is to run the bash script to update the tool which is ./update.sh.

When the script is fired the tool will start installing not only the necessary components, but it will also install many other tools that it uses to do the different searches it does and even offensive tools such as impacket and many others. The installation process takes a long time so we suggest a little patience and follow the installation step by step with a cup of coffee.
Running the tool
Once the installation and update of all the components are 100% finished, and we are standing in the installation directory, we can start using the tool, to do this we only need to run the script ./discover.sh with the sudo command in front, unless we are working with the root account directly

When the script is fired, the following screen will appear:
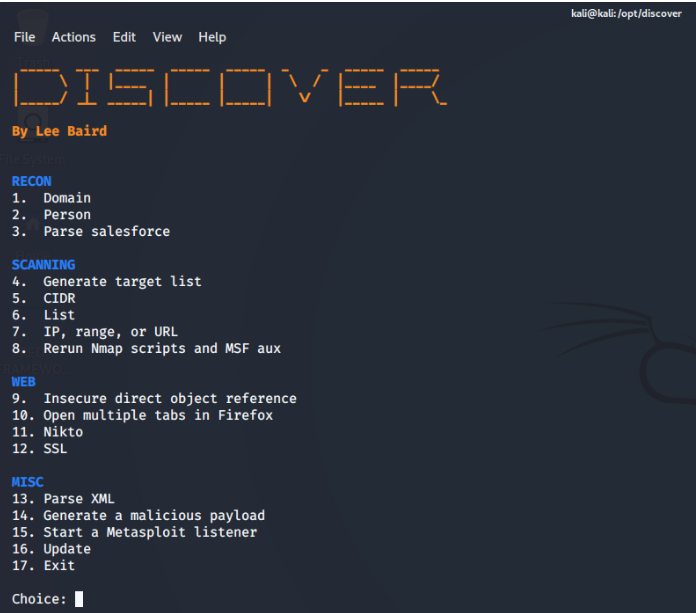
As we can see the tool has several options that are not only limited to "Reconnaissance" but can also invoke port scans with Nmap or even web scans with Nikto, just to mention some of the options.
We recommend looking at Lee Baird's GitHub website to see the documentation of the usage as it is quite extensive with everything that can be done with the tool. In our case, and given that we are talking about "Recognition" in the framework of a Red Team Engagement, we will only work with the "RECON" option.
Then we are going to mark inside RECON option 1 called Domain, that we just type the number 1 in the console and hit enter and the following menu will appear:
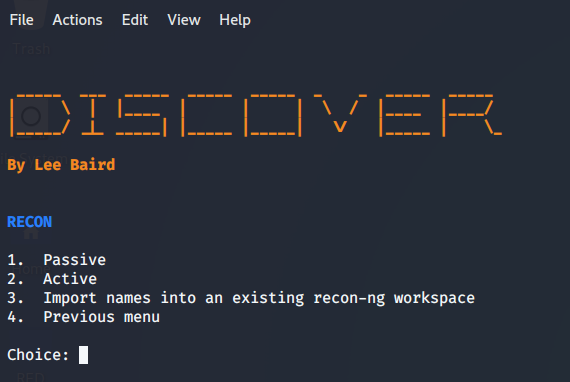
In this case, we are going to work with option 1 called "Passive" since we want to collect as much information as possible in a 100% passive way without the activity itself being detected in any way or another.
NOTE: If we type the option "Active" the search will use tool modules such as dnsrecon, WAF00W, traceroute, Whatweb, and recon-ng, which are not passive and could detect our activity and get our IP banned. We are going to take a valid domain since, in principle, we are doing absolutely nothing more than collecting information. For them, I am going to use the domain of https://www.nintendo.com/.
For this then, after selecting option 1 of "Passive" as we said before, we will be asked to enter the name of the company (This serves for the name of the report that the tool will create once finished) and on the other hand the domain name, which must be entered with the format "domain.com" ie without www or http. In our case "Nintendo.com".
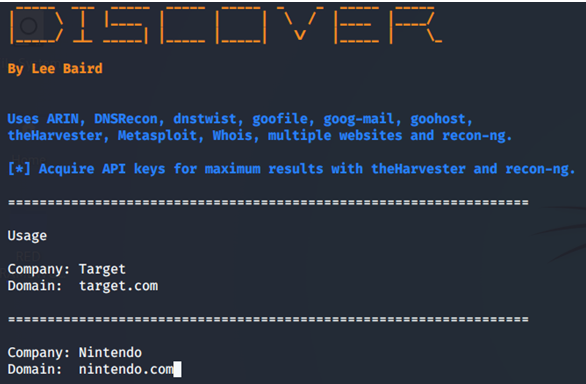
If we pay attention we can see the image that the tool tells us that it will use among other tools ARIN, DNSRecon, dnstwist, TheHarvester, recon-ng, and several more and even tells us that if we want to generate APIs to maximize the result we do it, which we recommend both for BING, Google CSE, Shodan, Censys, etc.
The APIs that we have generated can be loaded in the different tools that are used, in this case above all recon-ng and theharvester, with which the APIs would be loaded as follows:
In recon-ng you can use the command "show keys" and then enter the APIs with the command "keys add", for example: "keys add bing_api
".
Once we hit "enter" the tool starts running, so here we recommend another coffee. We will see that it starts running and making different queries through different tools:
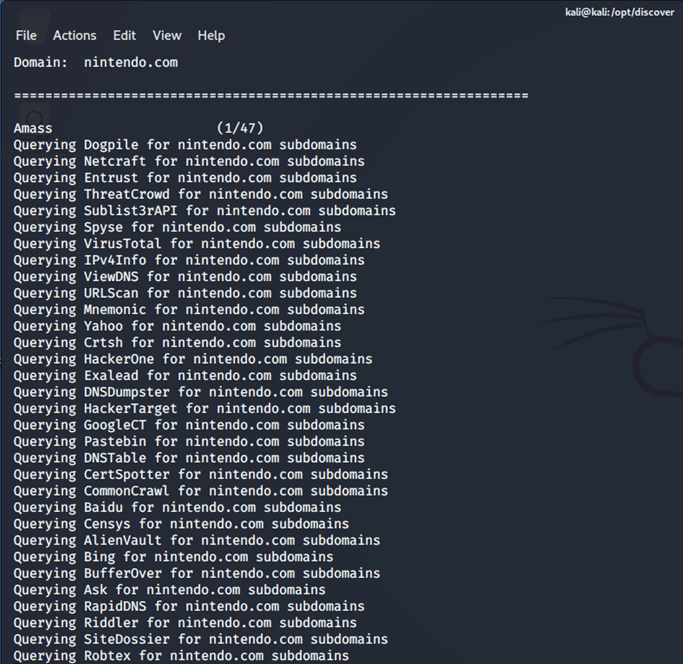
Once the tool finishes working it will say "Scan Complete" and it will show us in which path the file is saved, in this case inside /root/data/Nintendo.com which is the domain we specified.
From a console as root, we then fire Firefox to the index.html file generated inside /root/data/Nintendo.com/ and we will see in the browser the following:
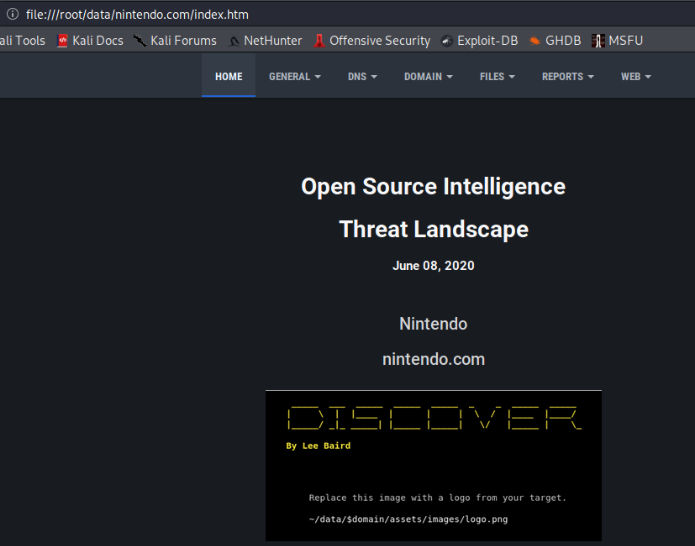
We can observe on the screen that several tabs are generated where we have the "Home", "General", "DNS", "Domain", "File", "Reports" and "Web". In general, we will be able to find a list of users and e-mails that can be used to create a customized dictionary, although much of this information must be validated.
We suggest that this is done directly by searching for information on the official site of the company or entity that you are looking at at that time as through scraping techniques such as Linkedin users of that company (Which we will see later in another post). In the case of DNS, we start to see the maps and DNS records belonging to the company or entity, as can be seen below.
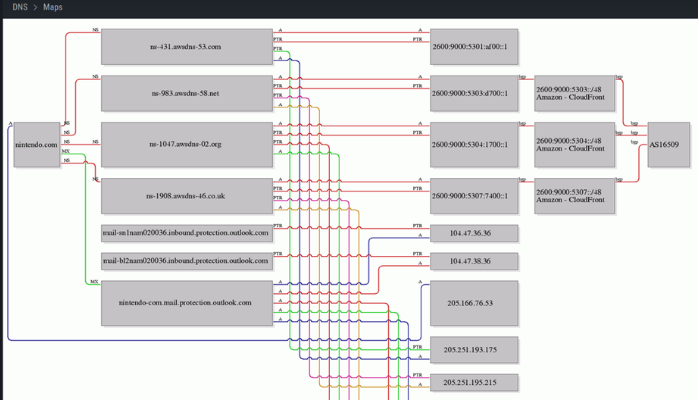
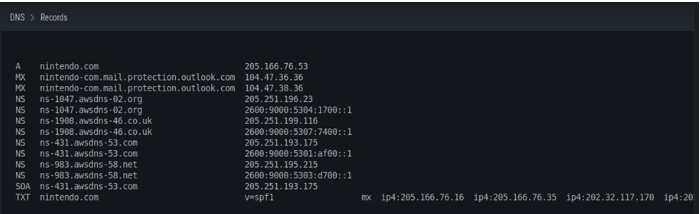
We can also see within this context other DNS domains registered by the company, in this case used as corporate mail.
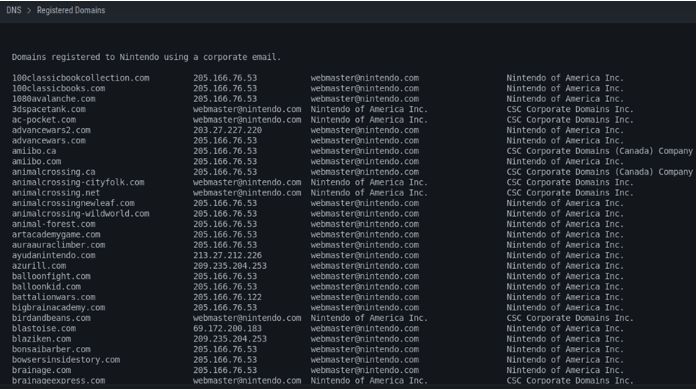
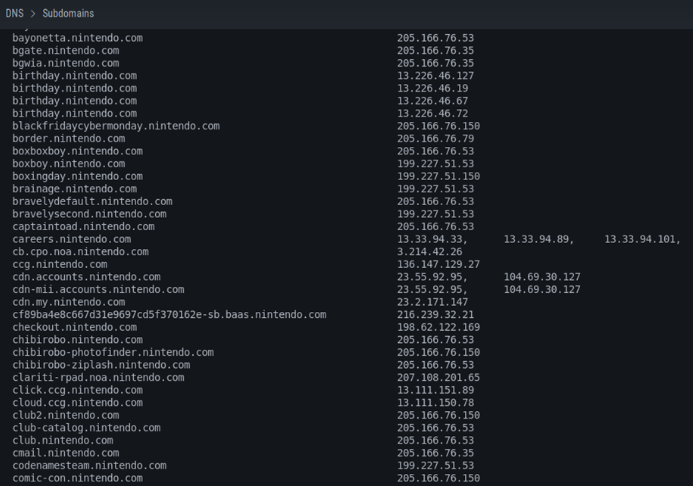
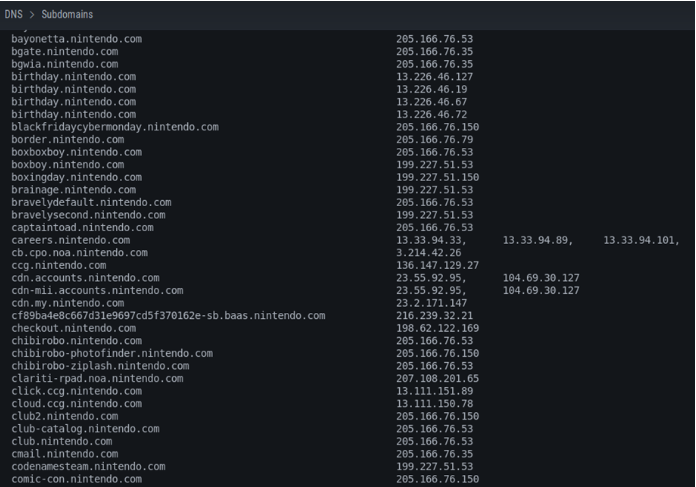
Also, the subdomains, which in this particular case we can see that there are many given that it is an extremely large company.
In the "Files" tab we can see that the tool shows us all the public files, in this case, we select the PDF option among all that it offers us. This is extremely useful since we could complementarily download many of these files with tools such as Foca or Metagoofil to extract additional useful data through the metadata of the files.
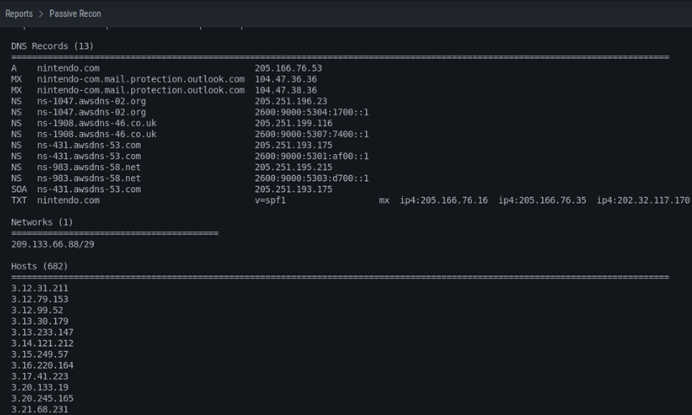
Finally (at least as far as this post is concerned) we can also see that, when we go to the "Reports" tab, two options are displayed, one of which is "Active Recon" and the second one is "Passive Recon". In this case, and given that from the beginning we only ran a Passive Recon for the "Domain" option, this will be the option we will select. When we do so, we will see that it shows us a detailed summary of everything it found in a very useful way to follow.
Conclusions
This tool, along with the use of recon-ng in an automated way, I use it a lot to collect information. As any "fat button" tool helps a lot to automate and collect a lot of information in a much shorter time than a purely manual search, however, it must be remembered:
- Much of the data must be manually re-validated.
- That the part of data from mailboxes and people should be extracted by other means or by some specific recon-ng modules that we will see later, or even by scraping.
- That the APIs that we have already registered (Shodan, Censys, Bing, GoogleCSE, Virustotal, etc.) should be used in recon-ng as well as in "TheHarvester" tool since the search generated by the tool will be much richer.
Remember also that the tool can automate active scans, automate the use of metasploit through modules that invoke, automate web scans with Nikto and many more things because in addition to the automation of many of the tools that we mentioned at the beginning in the case of its use in Kali Linux uses and automates the "Penetration Tester Framework" (PTF).
I hope you liked the note. Happy hacking!