Básicos de Machine Learning
Introducción al Machine Learning¶
Definición¶
El Aprendizaje Automático (Machine learning) es una rama de la Inteligencia Artificial que se centra en la construcción de sistemas que pueden aprender de los datos, en lugar de seguir solo reglas programadas explícitamente.
Los sistemas de Machine Learning utilizan algoritmos para analizar datos, aprender de ellos y luego hacer predicciones, en lugar de ser programados específicamente para llevar a cabo la tarea. Por ejemplo, un modelo de Machine Learning podría ser entrenado para reconocer gatos al proporcionarle miles de imágenes con y sin gatos. Con suficientes ejemplos, el sistema "aprende" a distinguir las características que definen a un gato, así podría identificarlos en nuevas imágenes que nunca antes había visto.
Tipos de aprendizaje¶
Según cómo el modelo puede aprender a partir de los datos, existen varios tipos de aprendizaje:
Aprendizaje supervisado¶
Los modelos son entrenados en un conjunto de datos etiquetado. Un conjunto de datos etiquetado es un conjunto de datos que contiene tanto los datos de entrada como las respuestas correctas, también conocidas como etiquetas o valores objetivo.
El objetivo del aprendizaje supervisado es aprender una función que transforme las entradas en salidas. Dependiendo del tipo de salida que queremos que el modelo sea capaz de generar, podemos dividir los modelos en varios tipos:
- Regresión (regression). Cuando la etiqueta o el valor objetivo es un número continuo (como el precio de una casa), el problema se considera un problema de regresión. El modelo debe devolver un número en una escala infinita.
- Clasificación (classification). Cuando la etiqueta es categórica (como predecir si un correo es spam o no), el problema es de clasificación. El modelo debe devolver una etiqueta según se corresponda a una clase u otra.
Algunos ejemplos de modelos fundamentados en este tipo de aprendizaje son:
- Regresión logística y lineal.
- Árboles de decisión.
- Clasificador "Naive Bayes".
- Máquinas de Vectores de Soporte.
Aprendizaje no supervisado¶
En este tipo de aprendizaje, en contraposición a lo que sucedía con el anterior, los modelos se entrenan usando un conjunto de datos sin etiquetas. En este tipo de aprendizaje, el objetivo es encontrar patrones o estructuras ocultas en los datos.
Puesto que en este tipo de aprendizaje no hay etiquetas, los modelos deben descubrir por sí mismos las relaciones en los datos.
Algunos ejemplos de modelos fundamentados en este tipo de aprendizaje son:
- Agrupamiento (clustering).
- Reducción de la dimensionalidad.
Aprendizaje por refuerzo¶
En este aprendizaje el modelo (también llamado agente) aprende a tomar decisiones óptimas a través de la interacción con su entorno. El objetivo es maximizar alguna noción de recompensa acumulativa.
En el aprendizaje por refuerzo, el agente toma acciones, las cuales afectan el estado del ambiente, y recibe retroalimentación en forma de recompensas o penalizaciones. La meta es aprender una estrategia para maximizar su recompensa a largo plazo.
Un ejemplo de este tipo de aprendizaje es un programa que aprenda a jugar al ajedrez. El agente (el programa) decide qué movimiento hacer (las acciones de mover ficha) en diferentes posiciones del tablero de ajedrez (los estados) para maximizar la posibilidad de ganar el juego (la recompensa).
Este tipo de aprendizaje es diferente de los dos anteriores. En lugar de aprender a partir de un conjunto de datos con o sin etiquetas, el aprendizaje por refuerzo está centrado en tomar decisiones óptimas y aprender a partir de la retroalimentación de esas decisiones.
Conjuntos de datos¶
Los datos son una pieza fundamental en cualquier algoritmo de Machine Learning. Sin ellos, independientemente del tipo de aprendizaje o modelo, no existe forma de iniciar ningún proceso de aprendizaje.
Un conjunto de datos es una colección que normalmente se representa en forma de tabla. En esta tabla, cada fila representa una observación o instancia y cada columna representa una característica, atributo o variable de esa observación. Este conjunto de datos es utilizado para entrenar y evaluar modelos:
- Entrenamiento del modelo. Un modelo de Machine Learning aprende a partir de un conjunto de datos de entrenamiento. El modelo entrena ajustando sus parámetros internamente.
- Evaluación del modelo. Una vez que el modelo ha sido entrenado, se utiliza un conjunto de datos de prueba independiente para evaluar su rendimiento. Este dataset contiene observaciones que no se utilizaron durante el entrenamiento, lo que permite obtener una evaluación imparcial de cómo se espera que el modelo realice predicciones sobre nuevos datos.
En algunas situaciones, también se utiliza un conjunto de validación, que se utiliza para evaluar el rendimiento de un modelo durante el entrenamiento. Una vez que se entrenan los modelos, se evalúan en el conjunto de validación para seleccionar el mejor modelo posible.
División del conjunto de datos¶
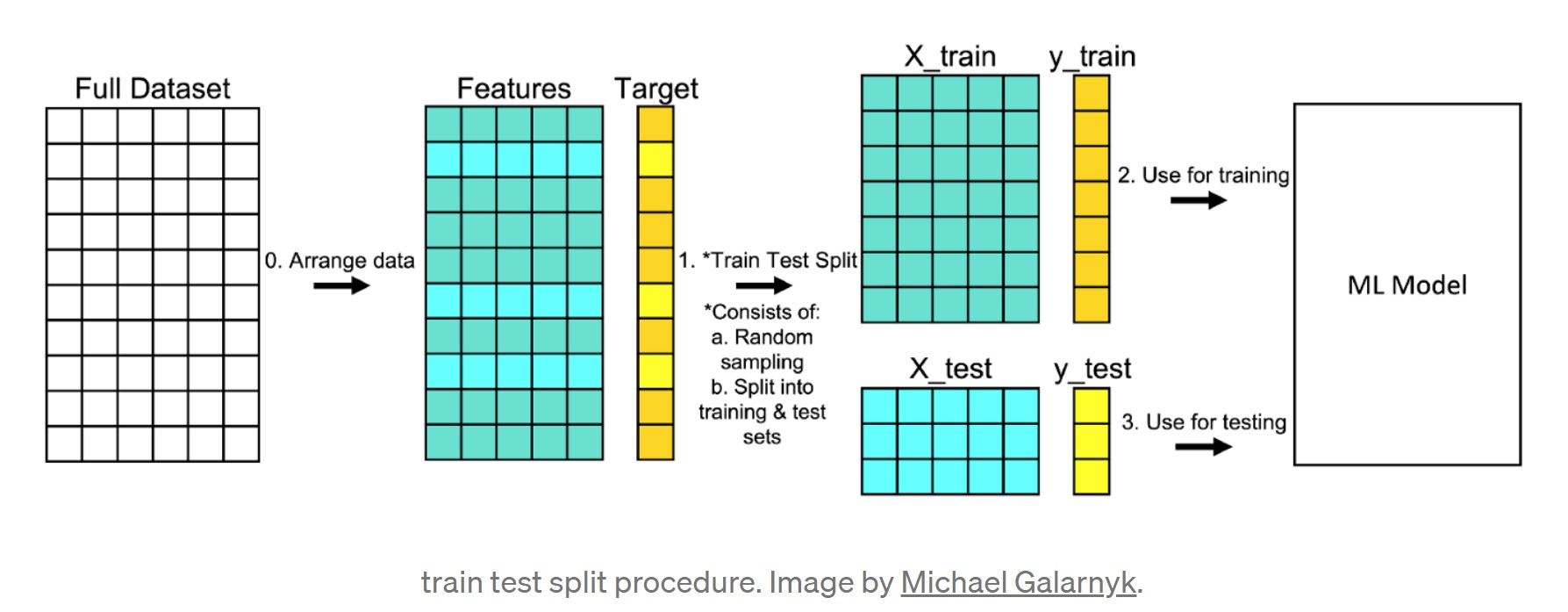
El paso previo de entrenar un modelo, además del EDA, es dividir los datos en un conjunto de entrenamiento (train dataset) y un conjunto de prueba (test dataset), en un procedimiento como el siguiente:
- Asegúrate de que tus datos estén organizados en un formato aceptable. Si trabajamos con ficheros de texto deberían ser formato de tabla, y si trabajamos con imágenes, los propios documentos en sí.
- Divide el conjunto de datos en dos partes: un conjunto de entrenamiento y un conjunto de prueba. Seleccionaremos aleatoriamente un 80% (puede variar) de las filas y las colocaremos en el conjunto de entrenamiento y el 20% restante en el conjunto de prueba. Además, debemos dividir las predictoras de las clases, conformando 4 elementos:
X_train,y_train,X_test,y_test. - Entrena el modelo usando el conjunto de entrenamiento (
X_train,y_train). - Prueba el modelo usando el conjunto de prueba (
X_test,y_test).
import seaborn as sns
from sklearn.model_selection import train_test_split
# Cargamos el conjunto de datos
total_data = sns.load_dataset("attention")
features = ["subject", "attention", "solutions"]
target = "score"
# Separamos las predictoras de la etiqueta
X = total_data[features]
y = total_data[target]
# Dividimos la muestra en train y test al 80%
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42, train_size = 0.80)
Sobreajuste de modelos¶
El sobreajuste (overfitting) se da cuando el modelo se entrena con muchos datos. Cuando un modelo se entrena con tantos datos, comienza a aprender del ruido y las entradas de datos inexactas de nuestro dataset. Debido a esto, el modelo no devuelve una salida acertada. Combatir el sobreajuste es una tarea iterativa y que deriva en la experiencia del desarrollador, y podemos empezar con:
- Realizar un correcto EDA, seleccionando valores y variables significativas para el modelo siguiendo la regla del "menos es más".
- Simplificar o cambiar el modelo que estamos utilizando.
- Usar más o menos datos de entrenamiento.
Detectar si el modelo está sobreajustando los datos es también una ciencia, y lo podemos determinar si la métrica del modelo en el conjunto de datos de entrenamiento es muy alta, y la métrica del conjunto de prueba es baja.
En cambio, si no hemos entrenado suficiente el modelo también podemos verlo simplemente comparando la métrica de entrenamiento y prueba, de tal forma que si son relativamente iguales y muy altos, lo más probable es que nuestro modelo no se ajuste bien a nuestros datos de entrenamiento.