Pandas Merge
El método merge() de Pandas se utiliza para combinar dos o más DataFrames en función de una o más columnas. Veamos como utilizar el método merge() a través del siguiente ejemplo:
import pandas as pd
# Crear DataFrame de empleados
df_employees = pd.DataFrame({'Employee_id': [1, 2, 3, 4],
'Name': ['Daniel', 'David', 'Carlos', 'Maria']})
# Crear DataFrame de proyectos
df_projects = pd.DataFrame({'Project_ID': [55, 88, 100],
'Employee_id': [1, 2, 3],
'Project': ['Análisis de Datos', 'Desarrollo Web', 'Desarrollo móvil']})
# Combinar DataFrames usando el método merge()
df_merged = pd.merge(df_employees, df_projects, on='Employee_id')
print(df_merged)(output) de la variable
df_merged
| Employee_id | Name | Project_ID | Project | |
|---|---|---|---|---|
| 0 | 1 | Daniel | 55 | Análisis de Datos |
| 1 | 2 | David | 88 | Desarrollo Web |
| 2 | 3 | Carlos | 100 | Desarrollo móvil |
En este ejemplo, se crean dos DataFrame, el DataFrame df_employees que incluye información de los empleados y el DataFrame df_projects que contiene información de los proyectos. Se utiliza el método merge() para combinar ambos Dataframes en base a la columna en común Employee_id, esto genera un nuevo DataFrame llamado df_merged que contendrá información de ambos DataFrames, finalmente se imprime por la terminal, donde se puede observar una tabla donde cada fila representa un proyecto y contiene los detalles del empleado asignado a ese proyecto.
Si te interesa aprender más sobre pandas con ejercicios interactivos, te recomendamos nuestro tutorial de pandas para machine learning
Método merge() en Pandas
En Pandas con el método merge() podemos combinar dos o más DataFrames, este método requiere que se le pasen ciertos parámetros para poder realizar la combinación de los DataFrames, estos parámetros son:
pd.merge(
left,
right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index: False,
right_index: False,
sort: False,
suffixes=('_x', '_y'),
copy=True,
indicator=False,
validate=None)-
left: Representa el primer DataFrame que se desea combinar (Requerido). -
right: Representa el segundo DataFrame que se desea combinar (Requerido). -
how: Representa el tipo de combinación que se desea realizar, puede serinner,outer,leftoright(Opcional). De no especificarse, su valor por defecto esinner.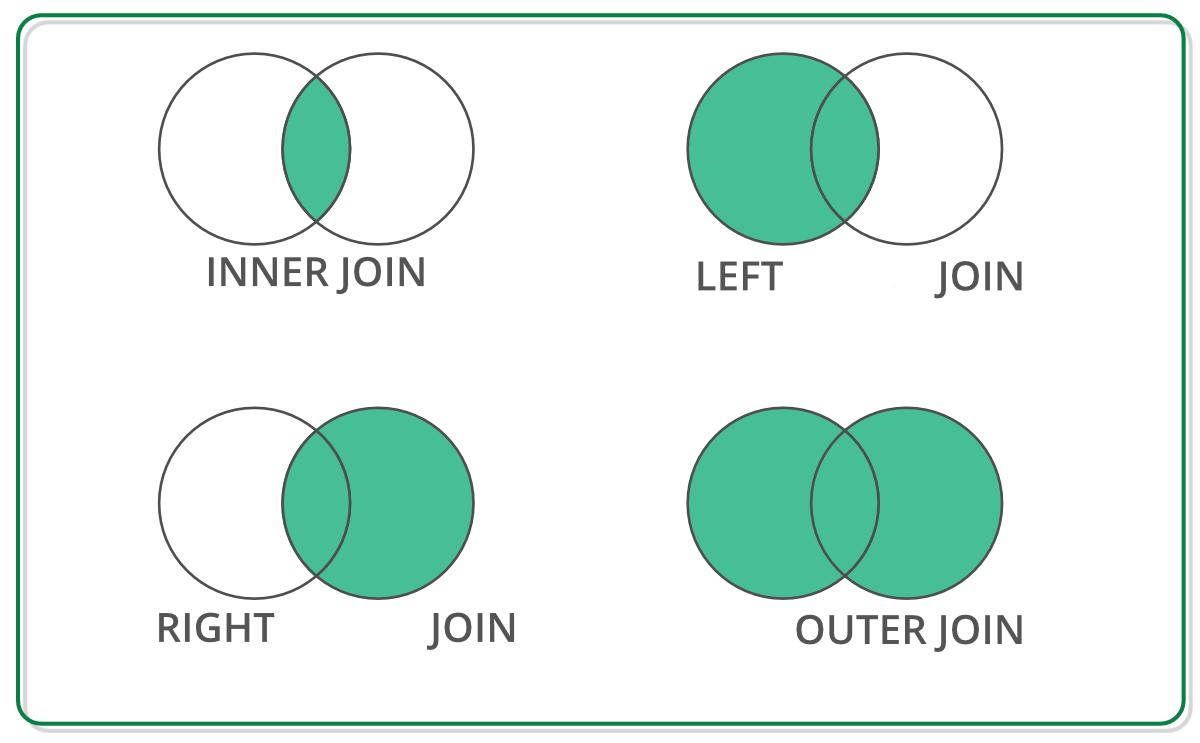
inner: Devuelve solo los registros que están en ambos DataFrames.outer: Devuelve todos los registros de ambos DataFrames.left: Devuelve todos los registros del DataFrame de la izquierda y los registros que están en ambos DataFrames.right: Devuelve todos los registros del DataFrame de la derecha y los registros que están en ambos DataFrames.
-
on: Representa el nombre de la columna en común que se utilizará para combinar ambos DataFrames (Opcional). -
left_onyright_on: Representan el nombre de las columnas en el DataFrame izquierdo y derecho respectivamente, que se utilizarán para combinar ambos DataFrames (Opcional). -
left_indexyright_index: Si se establecen enTrue, se utiliza el índice del DataFrame izquierdo y derecho respectivamente, para combinar ambos DataFrames (Opcional). De no especificarse sus valores por defecto seráFalse. -
sort: Si se establece enTruese ordenan los registros en base a la columna en común (Opcional). De no especificarse su valor por defecto esFalse. -
suffixes: Si se encuentran columnas con el mismo nombre en ambos DataFrames, se le agrega un sufijo a la columna del DataFrame de la izquierda y al DataFrame de la derecha (Opcional). De no especificarse su valor por defecto es('_x', '_y'). -
copy: Representa si se copia o no la información de los DataFrames (Opcional). De no especificarse su valor por defecto esTrue. -
indicator: Si esTruese agrega una columna_mergeque indica de que DataFrame proviene cada registro (Opcional). De no especificarse su valor por defecto esFalse. -
validate: Si se establece como valorone_to_onese valida que la combinación sea de uno a uno, si esone_to_manyse valida que la combinación sea de uno a muchos, si esmany_to_onese valida que la combinación sea de muchos a uno, si esmany_to_manyse valida que la combinación sea de muchos a muchos (Opcional).
Ejemplos de uso del método merge() en Pandas
Combinar DataFrames en base a una columna en común
import pandas as pd
# Crear DataFrame de jugadores mundialistas
df_world_cup_players = pd.DataFrame([
{"name": "Miroslav Klose", "country": "Germany", "position": "forward"},
{"name": "Ronaldo Nazario", "country": "Brazil", "position": "forward"},
{"name": "Luka Modric", "country": "Croatia", "position": "midfielder"},
{"name": "Erling Haaland", "country": "Norway", "position": "forward"},
{"name": "Lionel Messi", "country": "Argentina", "position": "forward"},
{"name": "Pelé", "country": "Brazil", "position": "forward"},
{"name": "Kylian Mbappé", "country": "France", "position": "forward"},
{"name": "Cristiano Ronaldo", "country": "Portugal", "position": "forward"}
])
# Crear DataFrame de máximos goleadores en mundiales
df_world_top_scorers = pd.DataFrame([
{"name": "Miroslav Klose", "world_cups": 4, "total_matches": 24, "champion": 1, "goals": 16},
{"name": "Ronaldo Nazario", "world_cups": 4, "total_matches": 19, "champion": 2, "goals": 15},
{"name": "Gerd Muller", "world_cups": 2, "total_matches": 13, "champion": 1, "goals": 14},
{"name": "Just Fontaine", "world_cups": 1, "total_matches": 6, "champion": 0, "goals": 13},
{"name": "Lionel Messi", "world_cups": 5, "total_matches": 26, "champion": 1, "goals": 13},
{"name": "Pelé", "world_cups": 4, "total_matches": 14, "champion": 3, "goals": 12},
{"name": "Kylian Mbappé", "world_cups": 2, "total_matches": 14, "champion": 1, "goals": 12},
{"name": "Sándor Kocsis", "world_cups": 1, "total_matches": 5, "champion": 0, "goals": 11},
])
# Combinar DataFrames usando merge() en base al nombre del jugador
df_merged = pd.merge(df_world_cup_players, df_world_top_scorers, on='name', how="inner")
# Mostrar el DataFrame combinado
print(df_merged)
(output) de la variable
df_merged
| name | country | position | world_cups | total_matches | champion | goals | |
|---|---|---|---|---|---|---|---|
| 0 | Miroslav Klose | Germany | forward | 4 | 24 | 1 | 16 |
| 1 | Ronaldo Nazario | Brazil | forward | 4 | 19 | 2 | 15 |
| 2 | Lionel Messi | Argentina | forward | 5 | 26 | 1 | 13 |
| 3 | Pelé | Brazil | forward | 4 | 14 | 3 | 12 |
| 4 | Kylian Mbappé | France | forward | 2 | 14 | 1 | 12 |
En este ejemplo, utilizamos el método merge() para combinar dos DataFrames, df_world_cup_players y df_world_top_scorers, en base a una columna en común, en este caso la columna name, a través del parámetro on. El resultado es un nuevo DataFrame con los registros que se encuentran en ambos DataFrames, debido a que utilizamos el parámetro how="inner". Por lo que se mostrarán solo los jugadores mundialistas que también son máximos goleadores en mundiales.
Combinar DataFrames en base a dos columnas que no tienen el mismo nombre
import pandas as pd
# Crear DataFrame de jugadores mundialistas
df_world_cup_players = pd.DataFrame([
{"name": "Miroslav Klose", "country": "Germany", "position": "forward"},
{"name": "Ronaldo Nazario", "country": "Brazil", "position": "forward"},
{"name": "Luka Modric", "country": "Croatia", "position": "midfielder"},
{"name": "Erling Haaland", "country": "Norway", "position": "forward"},
{"name": "Lionel Messi", "country": "Argentina", "position": "forward"},
{"name": "Pelé", "country": "Brazil", "position": "forward"},
{"name": "Kylian Mbappé", "country": "France", "position": "forward"},
{"name": "Cristiano Ronaldo", "country": "Portugal", "position": "forward"}
])
# Crear DataFrame de máximos goleadores en mundiales
df_world_top_scorers = pd.DataFrame([
{"player_name": "Miroslav Klose", "world_cups": 4, "total_matches": 24, "champion": 1, "goals": 16},
{"player_name": "Ronaldo Nazario", "world_cups": 4, "total_matches": 19, "champion": 2, "goals": 15},
{"player_name": "Gerd Muller", "world_cups": 2, "total_matches": 13, "champion": 1, "goals": 14},
{"player_name": "Just Fontaine", "world_cups": 1, "total_matches": 6, "champion": 0, "goals": 13},
{"player_name": "Lionel Messi", "world_cups": 5, "total_matches": 26, "champion": 1, "goals": 13},
{"player_name": "Pelé", "world_cups": 4, "total_matches": 14, "champion": 3, "goals": 12},
{"player_name": "Kylian Mbappé", "world_cups": 2, "total_matches": 14, "champion": 1, "goals": 12},
{"player_name": "Sándor Kocsis", "world_cups": 1, "total_matches": 5, "champion": 0, "goals": 11},
])
df_merged = pd.merge(df_world_cup_players, df_world_top_scorers, left_on='name', right_on="player_name", how="outer")
# Mostrar el DataFrame combinado
print(df_merged)
(output) de la variable
df_merged
| name | country | position | player_name | world_cups | total_matches | champion | goals | |
|---|---|---|---|---|---|---|---|---|
| 0 | Miroslav Klose | Germany | forward | Miroslav Klose | 4.0 | 24.0 | 1.0 | 16.0 |
| 1 | Ronaldo Nazario | Brazil | forward | Ronaldo Nazario | 4.0 | 19.0 | 2.0 | 15.0 |
| 2 | Luka Modric | Croatia | midfielder | NaN | NaN | NaN | NaN | NaN |
| 3 | Erling Haaland | Norway | forward | NaN | NaN | NaN | NaN | NaN |
| 4 | Lionel Messi | Argentina | forward | Lionel Messi | 5.0 | 26.0 | 1.0 | 13.0 |
| 5 | Pelé | Brazil | forward | Pelé | 4.0 | 14.0 | 3.0 | 12.0 |
| 6 | Kylian Mbappé | France | forward | Kylian Mbappé | 2.0 | 14.0 | 1.0 | 12.0 |
| 7 | Cristiano Ronaldo | Portugal | forward | NaN | NaN | NaN | NaN | NaN |
| 8 | NaN | NaN | NaN | Gerd Muller | 2.0 | 13.0 | 1.0 | 14.0 |
| 9 | NaN | NaN | NaN | Just Fontaine | 1.0 | 6.0 | 0.0 | 13.0 |
| 10 | NaN | NaN | NaN | Sándor Kocsis | 1.0 | 5.0 | 0.0 | 11.0 |
En este ejemplo, haciendo uso del método merge(), combinamos los Dataframes df_world_cup_players y df_world_top_scorers en base a las columnas name y player_name respectivamente, a través de los parámetros left_on y right_on. El resultado es un nuevo DataFrame con los registros que se encuentran en ambos DataFrames, debido a que utilizamos el parámetro how="outer". Por lo que se mostrarán todos los jugadores mundialistas y máximos goleadores en mundiales. En caso de que un jugador no se encuentre en ambos DataFrames, se mostrará un NaN en las columnas correspondientes.
Combinar DataFrames en base a los índices
import pandas as pd
# Crear DataFrame de jugadores mundialistas
df_world_cup_players = pd.DataFrame([
{"name": "Miroslav Klose", "country": "Germany", "position": "forward"},
{"name": "Ronaldo Nazario", "country": "Brazil", "position": "forward"},
{"name": "Luka Modric", "country": "Croatia", "position": "midfielder"},
{"name": "Erling Haaland", "country": "Norway", "position": "forward"},
])
# Crear DataFrame de estadísticas de jugadores mundialistas
df_player_stats = pd.DataFrame([
{"matches_played": 24, "goals_scored": 16},
{"matches_played": 19, "goals_scored": 15},
{"matches_played": 26, "goals_scored": 13},
{"matches_played": 14, "goals_scored": 12},
])
# Establecer el nombre de los jugadores como índices en ambos DataFrames
df_world_cup_players.set_index('name', inplace=True)
df_player_stats.set_index(df_world_cup_players.index, inplace=True)
# Combinar DataFrames usando merge() en base a los índices
df_merged = pd.merge(df_world_cup_players,df_player_stats, left_index=True, right_index=True)
# Mostrar el DataFrame combinado
print(df_merged)(output) de la variable
df_merged
| name | country | position | matches_played | goals_scored |
|---|---|---|---|---|
| Miroslav Klose | Germany | forward | 24 | 16 |
| Ronaldo Nazario | Brazil | forward | 19 | 15 |
| Luka Modric | Croatia | midfielder | 26 | 13 |
| Erling Haaland | Norway | forward | 14 | 12 |
En este ejemplo, haciendo uso del método merge(), combinamos los Dataframes df_world_cup_players y df_player_stats en base a los índices de ambos DataFrames, a través de los parámetros left_index y right_index. El resultado es un nuevo DataFrame con los registros que se encuentran en ambos DataFrames, debido a que la combinación se realiza en base a los índices. Por lo que se mostrarán todos los jugadores mundialistas y sus estadísticas.
Combinar DataFrames con nombres de columnas duplicados
import pandas as pd
# Crear DataFrame de jugadores mundialistas
df_world_cup_players = pd.DataFrame([
{"name": "Miroslav Klose", "country": "Germany", "position": "forward"},
{"name": "Ronaldo Nazario", "country": "Brazil", "position": "forward"},
{"name": "Luka Modric", "country": "Croatia", "position": "midfielder"},
{"name": "Erling Haaland", "country": "Norway", "position": "forward"},
{"name": "Lionel Messi", "country": "Argentina", "position": "forward"},
{"name": "Pelé", "country": "Brazil", "position": "forward"},
{"name": "Kylian Mbappé", "country": "France", "position": "forward"},
{"name": "Cristiano Ronaldo", "country": "Portugal", "position": "forward"}
])
# Crear DataFrame de máximos goleadores en mundiales
df_world_top_scorers = pd.DataFrame([
{"name": "Miroslav Klose", "world_cups": 4, "total_matches": 24, "goals": 16, "country": "Germany"},
{"name": "Ronaldo Nazario", "world_cups": 4, "total_matches": 19, "goals": 15, "country": "Brazil"},
{"name": "Gerd Muller", "world_cups": 2, "total_matches": 13, "goals": 14, "country": "Germany"},
{"name": "Just Fontaine", "world_cups": 1, "total_matches": 6, "goals": 13, "country": "France"},
{"name": "Lionel Messi", "world_cups": 5, "total_matches": 26, "goals": 13, "country": "Argentina"},
{"name": "Pelé", "world_cups": 4, "total_matches": 14, "goals": 12, "country": "Brazil"},
{"name": "Kylian Mbappé", "world_cups": 2, "total_matches": 14, "goals": 12, "country": "France"},
{"name": "Sándor Kocsis", "world_cups": 1, "total_matches": 5, "goals": 11, "country": "Hungary"},
])
df_merged = pd.merge(df_world_cup_players, df_world_top_scorers, on='name', how="left", suffixes=('_left', '_right'))
# Mostrar el DataFrame combinado
print(df_merged)(output) de la variable
df_merged
| name | country_left | position | world_cups | total_matches | goals | country_right | |
|---|---|---|---|---|---|---|---|
| 0 | Miroslav Klose | Germany | forward | 4.0 | 24.0 | 16.0 | Germany |
| 1 | Ronaldo Nazario | Brazil | forward | 4.0 | 19.0 | 15.0 | Brazil |
| 2 | Luka Modric | Croatia | midfielder | NaN | NaN | NaN | NaN |
| 3 | Erling Haaland | Norway | forward | NaN | NaN | NaN | NaN |
| 4 | Lionel Messi | Argentina | forward | 5.0 | 26.0 | 13.0 | Argentina |
| 5 | Pelé | Brazil | forward | 4.0 | 14.0 | 12.0 | Brazil |
| 6 | Kylian Mbappé | France | forward | 2.0 | 14.0 | 12.0 | France |
| 7 | Cristiano Ronaldo | Portugal | forward | NaN | NaN | NaN | NaN |
En este ejemplo, haciendo uso del método merge(), combinamos los Dataframes df_world_cup_players y df_world_top_scorers en base a la columna name de ambos DataFrames. El resultado es un nuevo DataFrame donde se conservarán todos los registros del DataFrame izquierdo debido a que utilizamos el parámetro how="left", y se agregan las columnas del DataFrame derecho. De no existir un registro en el DataFrame derecho, se mostrará un NaN. El parámetro suffixesnos permite agregar un sufijo cuando existen columnas con el mismo nombre en ambos DataFrames y así poder identificar de que DataFrame provienen, por ello observamos que existen columnas con el sufijo\_lefty\_right.
De esta forma también podríamos utilizar el parámetro how="right", para conservar todos los registros del DataFrame derecho y agregar las columnas del DataFrame izquierdo.
La capacidad de combinar DataFrames que nos brinda el método merge() es muy útil, es una herramienta poderosa en el análisis de datos, permitiéndoles por ejemplo a los científicos de datos, realizar análisis más profundos y complejos, obteniendo información simplificada y valiosa para tomar mejores decisiones.
Esperamos que hayas disfrutado de este artículo y que encuentres la información útil para mejorar el análisis de datos con Pandas. Te invitamos a explorar otros recursos en nuestro blog para ampliar tus conocimientos y habilidades con Pandas y la ciencia de datos. Si deseas llevar tu aprendizaje al siguiente nivel, te animamos a registrarte de forma totalmente gratuita en 4Geeks.com.