penetration testing
ciberseguridad
red team
Qué es el desbordamiento de búfer y como explotar esta vulnerabilidad
¿Qué es el desbordamiento del búfer?
Los buffers son regiones de almacenamiento de memoria que contienen datos temporalmente mientras se transfieren de una ubicación a otra. Un desbordamiento del búfer (o desbordamiento del búfer) ocurre cuando el volumen de datos excede la capacidad de almacenamiento del búfer de memoria. Como resultado, el programa que intenta escribir los datos en el búfer sobrescribe las ubicaciones de memoria adyacentes .
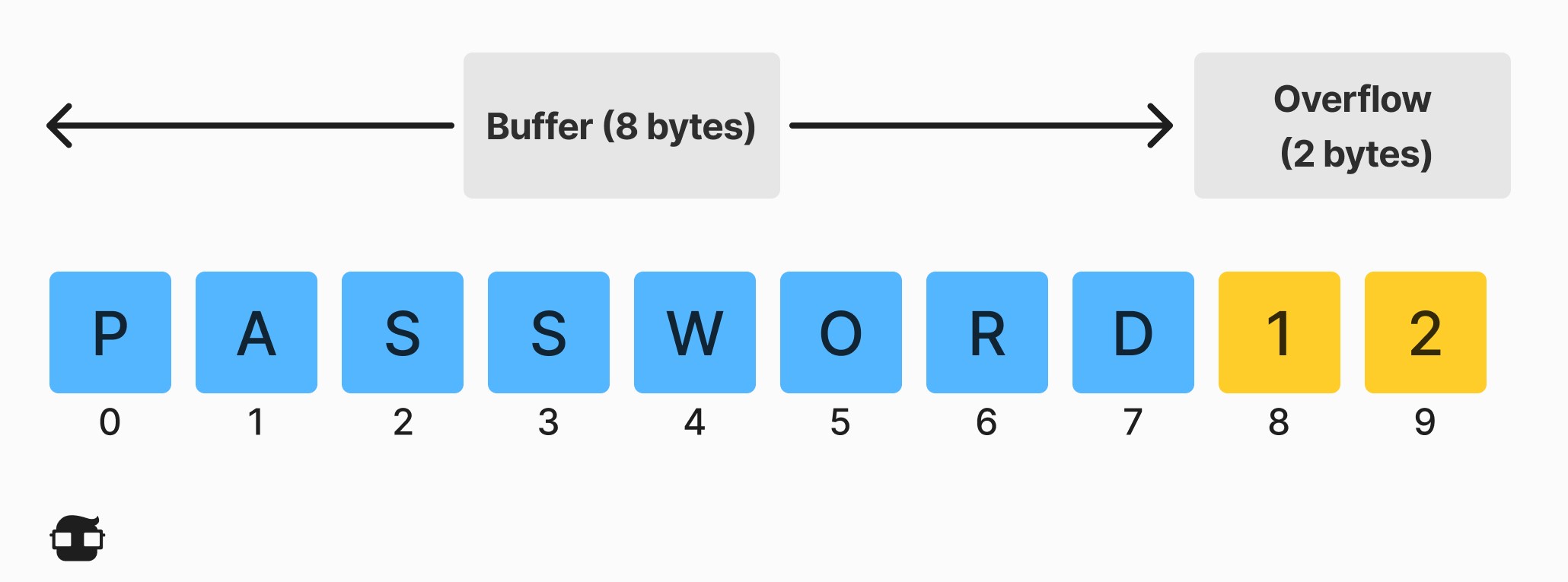
Por ejemplo, se puede diseñar un búfer para las credenciales de inicio de sesión para que espere entradas de nombre de usuario y contraseña de 8 bytes, de modo que si una transacción implica una entrada de 10 bytes (es decir, 2 bytes más de lo esperado), el programa puede escribir el exceso. datos más allá del límite del buffer.
Los desbordamientos de búfer pueden afectar a todo tipo de software. Por lo general, son el resultado de entradas con formato incorrecto o de no asignar suficiente espacio para el búfer. Si la transacción sobrescribe el código ejecutable, puede hacer que el programa se comporte de manera impredecible y genere resultados incorrectos, errores de acceso a la memoria o fallas.
Se produce un desbordamiento del búfer cuando un programa intenta escribir demasiados datos en el búfer. Esto puede hacer que el programa falle o ejecute código arbitrario. Las vulnerabilidades de desbordamiento de búfer existen sólo en lenguajes de programación de bajo nivel como C con acceso directo a la memoria. Sin embargo, también afectan a los usuarios de lenguajes web de alto nivel porque los marcos suelen estar escritos en lenguajes de bajo nivel. El siguiente es el código fuente de un programa en C que tiene una vulnerabilidad de desbordamiento del búfer:
1char greeting[5]; 2 3memcpy(greeting, "Hello, world!\n", 15); 4 5printf(greeting);
¿Qué crees que pasará cuando compilamos y ejecutamos este programa vulnerable? La respuesta puede resultar sorprendente: cualquier cosa puede pasar. Cuando se ejecuta este fragmento de código, intentará colocar quince bytes en un búfer de destino que tiene solo cinco bytes de longitud. Esto significa que se escribirán diez bytes en direcciones de memoria fuera de la matriz. Lo que suceda después depende del contenido original de los diez bytes de memoria sobrescritos.
¿Quizás se almacenaron variables importantes allí y acabamos de cambiar sus valores? El ejemplo anterior está roto de una manera tan obvia que ningún programador en su sano juicio cometería tal error. Entonces consideremos otro ejemplo. Supongamos que necesitamos leer una dirección IP de un archivo. Podemos hacerlo usando el siguiente código C:
1#include <stdio.h> 2 3#define MAX_IP_LENGTH 15 4 5int main(void) { 6 char file_name[] = "ip.txt"; 7 FILE *fp; 8 fp = fopen(file_name, "r"); 9 10 char ch; 11 int counter = 0; 12 char buf[MAX_IP_LENGTH]; 13 14 while ((ch = fgetc(fp)) != EOF) { 15 buf[counter++] = ch; 16 } 17 18 buf[counter] = '\0'; 19 printf("%s\n", buf); 20 21 fclose(fp); 22 return 0; 23}
El error en el ejemplo anterior no es tan obvio. Suponemos que la dirección IP que queremos leer de un archivo nunca excederá los 15 bytes. Las direcciones IP adecuadas (por ejemplo, 255.255.255.255) no pueden tener más de 15 bytes. Sin embargo, un usuario malintencionado puede preparar un archivo que contenga una cadena falsa muy larga en lugar de una dirección IP (por ejemplo, 19222222222.16888888.0.1). Esta cadena hará que nuestro programa desborde el búfer de destino.
¿Qué es un ataque de desbordamiento de búfer?
Los atacantes aprovechan los problemas de desbordamiento del búfer sobrescribiendo la memoria de una aplicación. Esto cambia la ruta de ejecución del programa, desencadenando una respuesta que daña archivos o expone información privada. Por ejemplo, un atacante puede introducir código adicional y enviar nuevas instrucciones a la aplicación para obtener acceso a los sistemas de TI.
Si los atacantes conocen el diseño de la memoria de un programa, pueden alimentar intencionalmente entradas que el búfer no puede almacenar y sobrescribir áreas que contienen código ejecutable, reemplazándolo con su propio código. Por ejemplo, un atacante puede sobrescribir un puntero (un objeto que apunta a otra área de la memoria) y apuntarlo a una carga útil de explotación para obtener control sobre el programa.
- Ejemplo de ataque de desbordamiento del buffer de pila.
Ahora que sabemos que un programa puede desbordar una matriz y sobrescribir un fragmento de memoria que no debería sobrescribir, veamos cómo se puede utilizar esto para montar un ataque de desbordamiento de búfer. En un escenario típico (llamado desbordamiento del búfer de pila), el problema se debe (como tantos problemas en la seguridad de la información) a la mezcla de datos (destinados a ser procesados o mostrados) con comandos que controlan la ejecución del programa. En C, como en la mayoría de los lenguajes de programación, los programas se crean utilizando funciones.
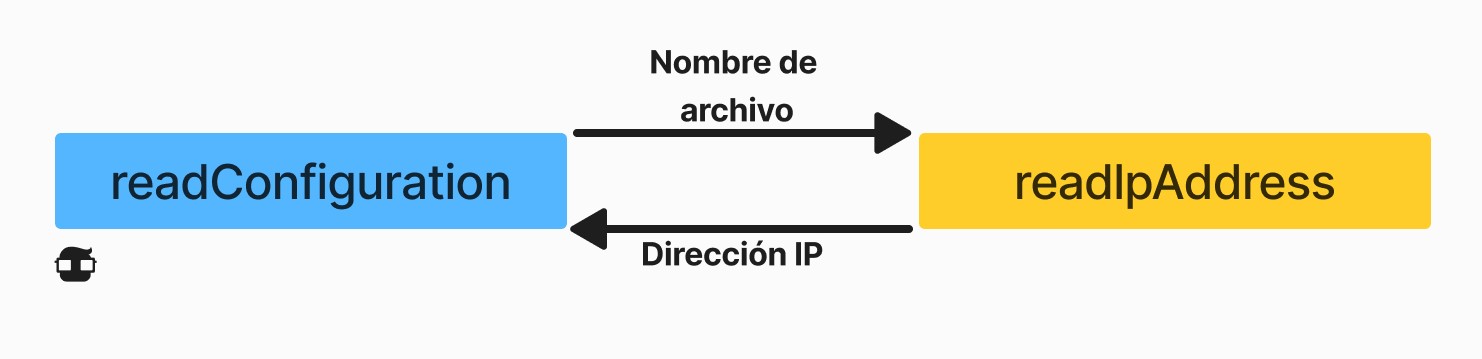
Las funciones se llaman entre sí, se pasan argumentos entre sí y devuelven valores. Por ejemplo, nuestro código, que lee una dirección IP de un archivo, podría ser parte de una función llamada readIpAddress, que lee una dirección IP de un archivo y la analiza. Esta función podría ser llamada por alguna otra función, por ejemplo readConfiguration. Cuando readConfigurationllama readIpAddress, le pasa un nombre de archivo y luego la readIpAddressfunción devuelve una dirección IP como una matriz de cuatro bytes. Fig. 1. Los argumentos y el valor de retorno de la función readIpAddress.
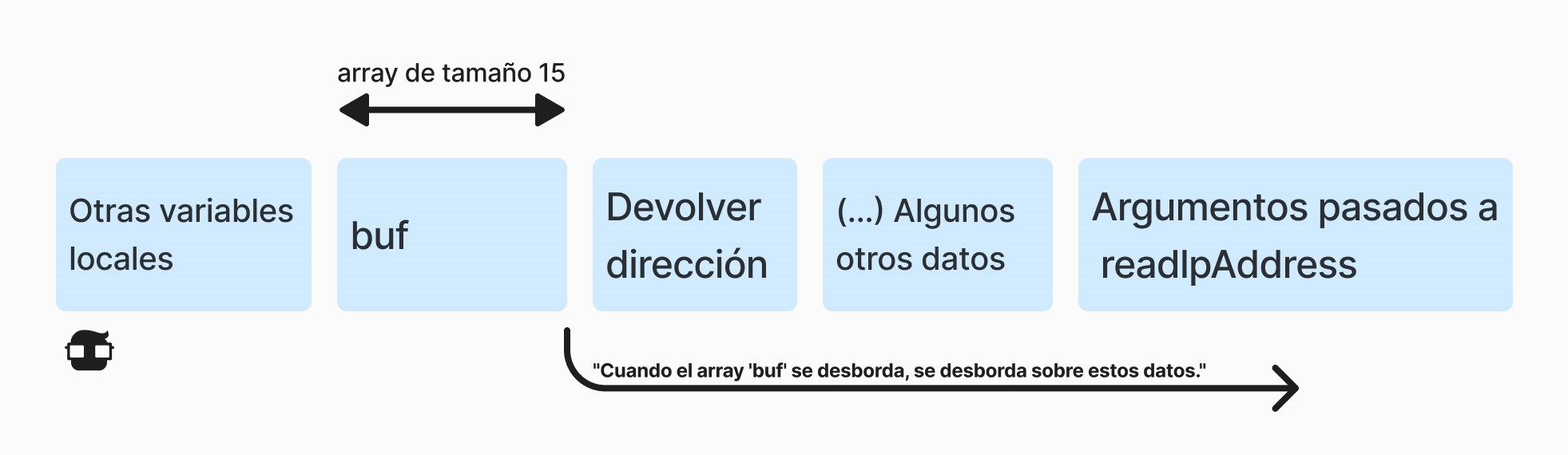
Durante esta llamada a función, se almacenan tres piezas diferentes de información, una al lado de la otra, en la memoria de la computadora. Para cada programa, el sistema operativo mantiene una región de memoria que incluye una parte llamada pila o pila de llamadas (de ahí el nombre de desbordamiento del búfer de pila). Cuando se llama a una función, se le asigna un fragmento de la pila. Esta pieza de la pila (llamada marco) se utiliza para:
- Recuerde la línea de código desde la cual se debe reanudar la ejecución del programa cuando se complete la ejecución de la función (en nuestro caso, será una línea específica de la readConfigurationfunción).
- Almacene los argumentos pasados a la función por su llamador (en nuestro caso, supongamos /home/someuser/myconfiguration/ip.txt).
- Almacene el valor de retorno que la función devuelve a su llamador (en nuestro caso, es una matriz de cuatro bytes, digamos (192, 168, 0, 1)).
- Almacenar variables locales de la función llamada mientras se ejecuta esta función (en nuestro caso, la variable char[MAX_IP_LENGTH] buf).
👉 Entonces, si un programa tiene un búfer asignado en el marco de la pila e intenta insertar más datos de los que caben allí, los datos ingresados por el usuario pueden desbordarse y sobrescribir la ubicación de la memoria donde se almacena la dirección del remitente. Contenido del marco de la pila cuando se llama a la función readIPAddress:
Si el problema fue causado por datos de entrada aleatorios mal formados del usuario, lo más probable es que la nueva dirección de retorno no apunte a una ubicación de memoria donde esté almacenado ningún otro programa, por lo que el programa original simplemente fallará. Sin embargo, si los datos se preparan cuidadosamente, pueden provocar la ejecución de código no deseada.
El primer paso para el atacante es preparar datos especiales que puedan interpretarse como código ejecutable y que funcionen en beneficio del atacante (esto se denomina código shell ). El segundo paso es colocar la dirección de estos datos maliciosos en la ubicación exacta donde debería estar la dirección del remitente. El contenido de ip.txt sobrescribe la dirección del remitente:
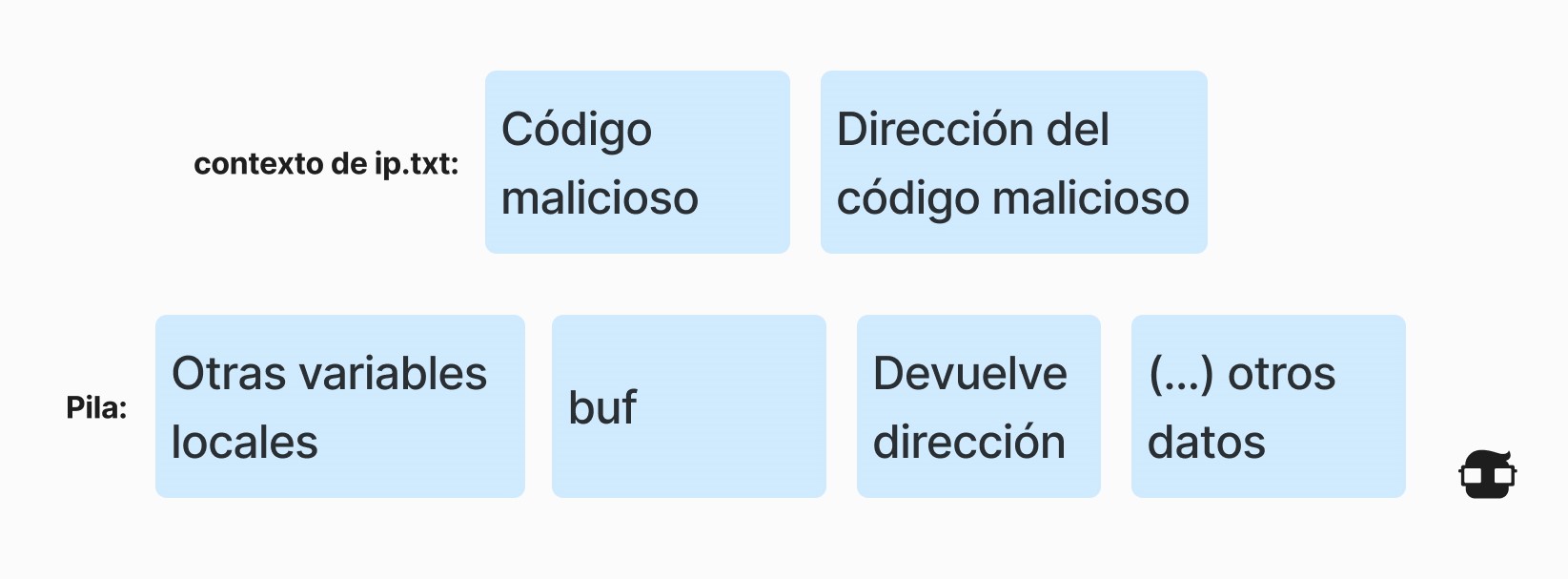
De hecho, cuando la función lee la cadena de caracteres IP y la coloca en el búfer de destino, la dirección de retorno se reemplaza por la dirección del código malicioso. Cuando finaliza la función, la ejecución del programa salta al código malicioso.
Tipos de ataques de desbordamiento de búfer
Los desbordamientos del búfer basados en pilas son más comunes y aprovechan la memoria de la pila que solo existe durante el tiempo de ejecución de una función.
Los ataques basados en montón son más difíciles de llevar a cabo e implican inundar el espacio de memoria asignado para un programa más allá de la memoria utilizada para las operaciones actuales en tiempo de ejecución.
¿Qué lenguajes de programación son más vulnerables?
C y C++ son dos lenguajes muy susceptibles a ataques de desbordamiento de búfer, ya que no tienen protecciones integradas contra la sobrescritura o el acceso a datos en su memoria. Mac OSX, Windows y Linux utilizan código escrito en C y C++.
Lenguajes como PERL, Java, JavaScript y C# utilizan mecanismos de seguridad integrados que minimizan la probabilidad de desbordamiento del búfer.
Cómo prevenir los desbordamientos del búfer
Los desarrolladores pueden protegerse contra las vulnerabilidades de desbordamiento del búfer mediante medidas de seguridad en su código o utilizando lenguajes que ofrecen protección integrada.
Además, los sistemas operativos modernos tienen protección en tiempo de ejecución. Tres protecciones comunes son:
- Aleatorización del espacio de direcciones (ASLR): se mueve aleatoriamente por las ubicaciones del espacio de direcciones de las regiones de datos. Normalmente, los ataques de desbordamiento de búfer necesitan conocer la localidad del código ejecutable, y la aleatorización de los espacios de direcciones hace que esto sea prácticamente imposible.
- Prevención de ejecución de datos: marca ciertas áreas de la memoria como no ejecutables o ejecutables, lo que impide que un ataque ejecute código en una región no ejecutable.
- Protección de sobrescritura del controlador de excepciones estructurado (SEHOP): ayuda a evitar que el código malicioso ataque el manejo de excepciones estructurado (SEH), un sistema integrado para administrar excepciones de hardware y software. De este modo, evita que un atacante pueda hacer uso de la técnica de explotación de sobrescritura SEH. A nivel funcional, una sobrescritura de SEH se logra utilizando un desbordamiento de búfer basado en pila para sobrescribir un registro de registro de excepción, almacenado en la pila de un subproceso.
Manténgase al día con los últimos informes de errores para sus productos de servidor web y de aplicaciones y otros productos en su infraestructura de Internet. Aplique los parches más recientes a estos productos. Escanee periódicamente su sitio web con uno o más de los escáneres comúnmente disponibles que buscan fallas de desbordamiento del búfer en sus productos de servidor y sus aplicaciones web personalizadas.
Para el código de su aplicación personalizada, debe revisar todo el código que acepta entradas de los usuarios a través de la solicitud HTTP y asegurarse de que proporciona una verificación del tamaño adecuado en todas esas entradas. Esto se debe hacer incluso en entornos que no son susceptibles a este tipo de ataques, ya que entradas demasiado grandes que no se detectan aún pueden causar denegación de servicio u otros problemas operativos.
Las medidas de seguridad en el código y la protección del sistema operativo no son suficientes. Cuando una organización descubre una vulnerabilidad de desbordamiento del búfer, debe reaccionar rápidamente para parchear el software afectado y asegurarse de que los usuarios del software puedan acceder al parche.
Los programadores pueden mitigar el riesgo de ataques de desbordamiento del búfer validando siempre la longitud de la entrada del usuario. Sin embargo, una buena forma general de evitar las vulnerabilidades de desbordamiento del búfer es seguir utilizando funciones seguras que incluyan protección contra desbordamiento del búfer (que memcpy no la incluye). Estas funciones están disponibles en diferentes plataformas, por ejemplo, strlcpy, strlcat, snprintf(OpenBSD) o strcpy_s, strcat_s, sprintf_s(Windows).
Categorización de NVD
CWE-788: Acceso a la ubicación de la memoria después del final del búfer : esto suele ocurrir cuando un puntero o su índice se incrementa a una posición después del búfer; o cuando la aritmética de punteros da como resultado una posición después del búfer.
El desbordamiento de búfer es probablemente la forma más conocida de vulnerabilidad de seguridad del software. La mayoría de los desarrolladores de software saben qué es una vulnerabilidad de desbordamiento de búfer, pero los ataques de desbordamiento de búfer contra aplicaciones heredadas y recientemente desarrolladas siguen siendo bastante comunes. Parte del problema se debe a la amplia variedad de formas en que pueden ocurrir los desbordamientos del búfer, y parte se debe a las técnicas propensas a errores que se utilizan a menudo para evitarlos.
Los desbordamientos de búfer no son fáciles de descubrir e incluso cuando se descubre uno, generalmente es extremadamente difícil de explotar. Sin embargo, los atacantes han logrado identificar desbordamientos de búfer en una asombrosa variedad de productos y componentes.
En un exploit clásico de desbordamiento de búfer, el atacante envía datos a un programa, que los almacena en un búfer de pila de tamaño insuficiente. El resultado es que se sobrescribe la información de la pila de llamadas, incluido el puntero de retorno de la función. Los datos establecen el valor del puntero de retorno para que cuando la función regrese, transfiera el control al código malicioso contenido en los datos del atacante.
Aunque este tipo de desbordamiento del búfer de pila sigue siendo común en algunas plataformas y en algunas comunidades de desarrollo, existe una variedad de otros tipos de desbordamiento del búfer, incluido el desbordamiento del búfer de montón y el error de uno por uno, entre otros. Otra clase de falla muy similar se conoce como ataque de cadena de formato . Hay varios libros excelentes que brindan información detallada sobre cómo funcionan los ataques de desbordamiento de búfer, incluidos Building Secure Software, Writing Secure Code y The Shellcoder's Handbook.
A nivel de código, las vulnerabilidades de desbordamiento del búfer generalmente implican la violación de las suposiciones del programador. Muchas funciones de manipulación de memoria en C y C++ no realizan verificación de límites y pueden sobrescribir fácilmente los límites asignados de los búferes sobre los que operan. Incluso las funciones limitadas, como strncpy(), pueden causar vulnerabilidades cuando se usan incorrectamente. La combinación de manipulación de la memoria y suposiciones erróneas sobre el tamaño o la composición de un dato es la causa principal de la mayoría de los desbordamientos del búfer.
Las vulnerabilidades de desbordamiento del búfer suelen ocurrir en código que:
- Se basa en datos externos para controlar su comportamiento.
- Depende de las propiedades de los datos que se aplican fuera del alcance inmediato del código.
- Es tan complejo que un programador no puede predecir con precisión su comportamiento.
Desde el descubrimiento de la técnica de ataque de desbordamiento del búfer de pila, los autores de sistemas operativos (Linux, Microsoft Windows, macOS y otros) han intentado encontrar técnicas de prevención:
- La pila se puede hacer no ejecutable, por lo que incluso si se coloca código malicioso en el búfer, no se puede ejecutar.
- El sistema operativo puede aleatorizar el diseño de la memoria del espacio de direcciones (espacio de memoria). Cuando el código malicioso se coloca en un búfer, el atacante no puede predecir su dirección.
- Otras técnicas de protección (por ejemplo, StackGuard) modifican un compilador de tal manera que cada función llama a un fragmento de código que garantiza que la dirección del remitente no haya cambiado.
En la práctica, incluso si dichos mecanismos de protección dificultan los ataques de desbordamiento del búfer de pila, no los hacen imposibles. Algunas de estas medidas también pueden afectar el rendimiento. Las vulnerabilidades de desbordamiento de búfer existen en lenguajes de programación que, como C, intercambian seguridad por eficiencia y no verifican el acceso a la memoria. En los lenguajes de programación de nivel superior (por ejemplo, Python, Java, PHP, JavaScript o Perl), que se utilizan a menudo para crear aplicaciones web, las vulnerabilidades de desbordamiento del búfer no pueden existir. En estos idiomas, simplemente no se pueden colocar datos sobrantes en el búfer de destino. Por ejemplo, intente compilar y ejecutar el siguiente código Java:
1int[] buffer = new int[5]; 2 3buffer[100] = 44;
El compilador de Java no le avisará, pero la máquina virtual Java en tiempo de ejecución detectará el problema y, en lugar de sobrescribir la memoria aleatoria, interrumpirá la ejecución del programa.
Desbordamiento de búfer y aplicaciones web
Los atacantes utilizan desbordamientos de búfer para corromper la pila de ejecución de una aplicación web. Al enviar información cuidadosamente diseñada a una aplicación web, un atacante puede hacer que la aplicación web ejecute código arbitrario, apoderándose efectivamente de la máquina.
Las fallas de desbordamiento de búfer pueden estar presentes tanto en el servidor web como en los productos del servidor de aplicaciones que atienden los aspectos estáticos y dinámicos del sitio, o en la aplicación web misma. Es probable que los desbordamientos de búfer que se encuentran en productos de servidor ampliamente utilizados se vuelvan ampliamente conocidos y puedan representar un riesgo significativo para los usuarios de estos productos. Cuando las aplicaciones web utilizan bibliotecas, como una biblioteca de gráficos para generar imágenes, se exponen a posibles ataques de desbordamiento del búfer.
Los desbordamientos de búfer también se pueden encontrar en el código de aplicaciones web personalizadas, e incluso pueden ser más probables dada la falta de escrutinio por el que suelen pasar las aplicaciones web. Es menos probable que se detecten fallas de desbordamiento de búfer en aplicaciones web personalizadas porque normalmente habrá muchos menos piratas informáticos que intenten encontrar y explotar dichas fallas en una aplicación específica. Si se descubre en una aplicación personalizada, la capacidad de explotar la falla (aparte de bloquear la aplicación) se reduce significativamente por el hecho de que el código fuente y los mensajes de error detallados de la aplicación normalmente no están disponibles para el pirata informático.
Sin embargo, incluso los programadores que utilizan lenguajes de alto nivel deberían conocer y preocuparse por los ataques de desbordamiento del búfer. Sus programas a menudo se ejecutan dentro de sistemas operativos escritos en C o utilizan entornos de ejecución escritos en C, y este código C puede ser vulnerable a tales ataques.
Para ver cómo una vulnerabilidad de desbordamiento de búfer puede afectar a un programador que utiliza un lenguaje de programación de tan alto nivel, analicemos CVE-2015-3329, una vulnerabilidad de seguridad de la vida real descubierta en la biblioteca estándar PHP en 2015. Una aplicación PHP es una colección de archivos *.php. Para facilitar la distribución de dicha aplicación, se puede empaquetar en un único archivo, como un archivo zip , un archivo tar o utilizando un formato PHP personalizado llamado phar.
Una extensión PHP llamada phar contiene una clase que puede utilizar para trabajar con dichos archivos. Con esta clase, puede analizar un archivo, enumerar sus archivos, extraerlos, etc. Usar esta clase es bastante simple. Por ejemplo, para extraer todos los archivos de un archivo, utilice el siguiente código:
1$phar = new Phar('phar-file.phar'); 2 3$phar->extractTo('./directory');
Cuando la clase Phar analiza un archivo (es decir new Phar('phar-file.phar')), lee todos los nombres de archivo del archivo, concatena cada nombre de archivo con el nombre del archivo y luego calcula la suma de verificación. Por ejemplo, para un archivo llamado myarchive.phar que contiene archivos index.php y componentes/hello.php, la clase Phar calcula sumas de verificación de dos cadenas: myarchive.pharindex.php y myarchive.pharcomponents/hello.php.
La razón por la que los autores lo implementaron de esta manera no es importante aquí; lo importante es cómo lo implementaron. Hasta 2015, esta operación se realizaba mediante la siguiente función (ver el antiguo código fuente PHP ):
1void phar_set_inode(phar_entry_info *entry TSRMLS_DC) 2{ 3 char tmp[MAXPATHLEN]; 4 int tmp_len; 5 6 tmp_len = entry->filename_len + entry->phar->fname_len; 7 8 memcpy(tmp, entry->phar->fname, entry->phar->fname_len); 9 memcpy(tmp + entry->phar->fname_len, entry->filename, entry->filename_len); 10 11 entry->inode = (unsigned short)zend_get_hash_value(tmp, tmp_len); 12}
Como puede ver, esta función crea una matriz char de llamados tmp. Primero, el nombre del archivo phar (en nuestro ejemplo, myarchive.phar ) se copia en esta matriz usando el siguiente comando:
1memcpy(tmp,entry->phar->fname,entry->phar->fname_len);
En este comando:
- El primer argumento, tmpes un destino donde se deben copiar los bytes.
- El segundo argumento, entry->phar->fname, es una fuente desde donde se deben copiar los bytes; en nuestro caso, el nombre del archivo ( myarchive.phar ).
- El tercer argumento, entry->phar->fname_lenes una cantidad de bytes que deben copiarse; en nuestro caso, es la longitud (en bytes) del nombre del archivo comprimido.
La función copia el nombre del archivo (en nuestro ejemplo, index.php o componentes/hello.php ) en la tmpmatriz de caracteres usando el siguiente comando:
1memcpy(tmp + entry->phar->fname_len, entry->filename, entry->filename_len);
En este comando:
- El primer argumento, tmp + entry->phar->fname_lenes un destino donde se deben copiar los bytes; en nuestro caso, es una ubicación en la tmpmatriz justo después del final del nombre del archivo.
- El segundo argumento, entry->filenamees una fuente desde donde se deben copiar los bytes.
- El tercer argumento, entry->filename_lenes una cantidad de bytes que deben copiarse.
Luego zend_get_hash_valuese llama a la función para calcular el código hash. Observe cómo se declara el tamaño del búfer:
char tmp[MAXPATHLEN];
Tiene un tamaño de MAXPATHLEN, que es una constante definida como la longitud máxima de una ruta del sistema de archivos en la plataforma actual. Los autores asumieron que si concatenan el nombre del archivo con el nombre de un archivo dentro del archivo, nunca excederán la longitud de ruta máxima permitida. En situaciones normales, este supuesto se cumple. Sin embargo, si el atacante prepara un archivo con nombres inusualmente largos, es inminente un desbordamiento del búfer.
La función phar_set_inode provocará un desbordamiento en la matriz tmp. Un atacante puede usar esto para bloquear PHP (provocando una denegación de servicio) o incluso hacer que ejecute código malicioso. El problema es similar a nuestro ejemplo simple de arriba: el programador cometió un simple error, confió demasiado en la entrada del usuario y asumió que los datos siempre cabrían en un búfer de tamaño fijo. Afortunadamente, esta vulnerabilidad fue descubierta en 2015 y solucionada .
Consecuencias
- Categoría: Disponibilidad: los desbordamientos del búfer generalmente provocan fallos. Son posibles otros ataques que provoquen falta de disponibilidad, incluido poner el programa en un bucle infinito.
- Control de acceso (procesamiento de instrucciones): los desbordamientos del búfer a menudo se pueden utilizar para ejecutar código arbitrario, que generalmente está fuera del alcance de la política de seguridad implícita de un programa.
- Otro: cuando la consecuencia es la ejecución de código arbitrario, esto a menudo puede usarse para subvertir cualquier otro servicio de seguridad.
Periodo de exposición
- Especificación de requisitos: Se podría optar por utilizar un lenguaje que no sea susceptible a estos problemas.
- Diseño: Se podrían introducir tecnologías de mitigación, como bibliotecas de cadenas seguras y abstracciones de contenedores.
- Implementación: muchos errores lógicos pueden provocar esta condición. Puede verse exacerbado por la falta o el mal uso de tecnologías de mitigación.
Ambientes afectados
Casi todos los servidores web, servidores de aplicaciones y entornos de aplicaciones web conocidos son susceptibles a desbordamientos de búfer, con la excepción notable de los entornos escritos en lenguajes interpretados como Java o Python, que son inmunes a estos ataques (excepto los desbordamientos en el propio Interpretor).
Plataforma
- Idiomas: C, C++, Fortran, Ensamblador
- Plataformas operativas: Todas, aunque se podrán implementar medidas preventivas parciales, dependiendo del entorno.
Cómo determinar si eres vulnerable
Para productos de servidor y bibliotecas, manténgase actualizado con los últimos informes de errores de los productos que está utilizando. Para el software de aplicación personalizado, todo el código que acepta entradas de los usuarios a través de la solicitud HTTP debe revisarse para garantizar que pueda manejar adecuadamente entradas arbitrariamente grandes.
- Ejemplo 1
El siguiente código de ejemplo demuestra un desbordamiento de búfer simple que a menudo es causado por el primer escenario en el que el código depende de datos externos para controlar su comportamiento. El código utiliza la función get() para leer una cantidad arbitraria de datos en un búfer de pila. Debido a que no hay forma de limitar la cantidad de datos leídos por esta función, la seguridad del código depende de que el usuario ingrese siempre menos de caracteres BUFSIZE.
1... 2 3char buf[BUFSIZE]; 4 5gets(buf); 6 7...
Este ejemplo muestra lo fácil que es imitar el comportamiento inseguro de la función gets() en C++ utilizando el >>operador para leer la entrada en una cadena char[].
1... 2 3char buf[BUFSIZE]; 4 5cin >> (buf); 6 7...
- Ejemplo 2
El código de este ejemplo también se basa en la entrada del usuario para controlar su comportamiento, pero agrega un nivel de direccionamiento indirecto con el uso de la función de copia de memoria limitada memcpy(). Esta función acepta un búfer de destino, un búfer de origen y la cantidad de bytes para copiar. El búfer de entrada se llena mediante una llamada limitada a read(), pero el usuario especifica el número de bytes que copia memcpy().
1... 2 3char buf[64], in[MAX_SIZE]; 4 5printf("Enter buffer contents:\n"); 6 7read(0, in, MAX_SIZE - 1); 8 9printf("Bytes to copy:\n"); 10 11scanf("%d", &bytes); 12 13memcpy(buf, in, bytes); 14 15...
Nota: Este tipo de vulnerabilidad de desbordamiento del búfer (donde un programa lee datos y luego confía en un valor de los datos en operaciones de memoria posteriores sobre los datos restantes) ha aparecido con cierta frecuencia en bibliotecas de procesamiento de imágenes, audio y otros archivos.
- Ejemplo 3
Este es un ejemplo del segundo escenario en el que el código depende de propiedades de los datos que no se verifican localmente. En este ejemplo, una función denominada lccopy() toma una cadena como argumento y devuelve una copia de la cadena asignada al montón con todas las letras mayúsculas convertidas a minúsculas. La función realiza una verificación sin límites en su entrada porque espera que str siempre sea menor que BUFSIZE. Si un atacante pasa por alto las comprobaciones en el código que llama a lccopy(), o si un cambio en ese código hace que la suposición sobre el tamaño de str sea falsa, entonces lccopy() se desbordará buf con la llamada ilimitada a strcpy().
1char *lccopy(const char *str) { 2 char buf[BUFSIZE]; 3 char *p; 4 5 strcpy(buf, str); 6 7 for (p = buf; *p; p++) { 8 if (isupper(*p)) { 9 *p = tolower(*p); 10 } 11 } 12 13 return strdup(buf); 14}
- Ejemplo 4
El siguiente código demuestra el tercer escenario en el que el código es tan complejo que su comportamiento no se puede predecir fácilmente. Este código proviene del popular decodificador de imágenes libPNG, que es utilizado por una amplia gama de aplicaciones, incluidas Mozilla y algunas versiones de Internet Explorer.
El código parece realizar la verificación de límites de manera segura porque verifica el tamaño de la longitud variable, que luego usa para controlar la cantidad de datos copiados por png_crc_read(). Sin embargo, inmediatamente antes de probar la longitud, el código realiza una verificación png_ptr->modey, si esta verificación falla, se emite una advertencia y el procesamiento continúa. Debido a que la longitud se prueba en un bloque else if, la longitud no se probará si la primera verificación falla y se usa ciegamente en la llamada a png_crc_read(), lo que potencialmente permite un desbordamiento del búfer de pila.
Aunque el código de este ejemplo no es el más complejo que hemos visto, demuestra por qué se debe minimizar la complejidad en el código que realiza operaciones de memoria.
1if (!(png_ptr->mode & PNG_HAVE_PLTE)) { 2 /* Debería ser un error, pero podemos solucionarlo. */ 3 png_warning(png_ptr, "Missing PLTE before tRNS"); 4} else if (length > (png_uint_32)png_ptr->num_palette) { 5 png_warning(png_ptr, "Incorrect tRNS chunk length"); 6 png_crc_finish(png_ptr, length); 7 return; 8} 9 10... 11 12png_crc_read(png_ptr, readbuf, (png_size_t)length);
- Ejemplo 5
Este ejemplo también demuestra el tercer escenario en el que la complejidad del programa lo expone a desbordamientos del búfer. En este caso, la exposición se debe a la interfaz ambigua de una de las funciones y no a la estructura del código (como fue el caso en el ejemplo anterior).
La getUserInfo() función toma un nombre de usuario especificado como una cadena multibyte y un puntero a una estructura para información del usuario, y completa la estructura con información sobre el usuario. Dado que la autenticación de Windows utiliza Unicode para los nombres de usuario, el argumento del nombre de usuario primero se convierte de una cadena multibyte a una cadena Unicode. Luego, esta función pasa incorrectamente el tamaño en unicodeUser bytes en lugar de caracteres.
Por lo tanto, la llamada a MultiByteToWideChar() puede escribir hasta (UNLEN+1)*sizeof(WCHAR)caracteres anchos, o (UNLEN+1)*sizeof(WCHAR)*sizeof(WCHAR)bytes, en la matriz unicodeUser, que solo tiene (UNLEN+1)*sizeof(WCHAR)bytes asignados. Si la cadena del nombre de usuario contiene más de UNLENcaracteres, la llamada a MultiByteToWideChar() desbordará el búfer unicodeUser.
Claro, aquí tienes el fragmento de código ordenado en Markdown:
1void getUserInfo(char *username, struct _USER_INFO_2 info) { 2 3 WCHAR unicodeUser[UNLEN+1]; 4 5 MultiByteToWideChar(CP_ACP, 0, username, -1, unicodeUser, sizeof(unicodeUser)); 6 7 NetUserGetInfo(NULL, unicodeUser, 2, (LPBYTE *)&info); 8 9}
Ataque de desbordamiento de búfer
Los errores de desbordamiento de búfer se caracterizan por la sobrescritura de fragmentos de memoria del proceso, que nunca debieron haber sido modificados de forma intencionada o no. La sobrescritura de valores de IP (puntero de instrucción), BP (puntero base) y otros registros provoca excepciones, fallas de segmentación y otros errores. Generalmente estos errores finalizan la ejecución de la aplicación de forma inesperada. Los errores de desbordamiento del búfer ocurren cuando operamos con búferes de tipo char.
Los desbordamientos del búfer pueden consistir en desbordar la pila [Stack overflow] o desbordar el montón [Heap overflow]. No distinguimos entre estos dos en este artículo para evitar confusiones. Los siguientes ejemplos están escritos en lenguaje C bajo el sistema GNU/Linux en arquitectura x86.
- Ejemplo 1
1#include <stdio.h> 2 3int main(int argc, char **argv) { 4 char buf[8]; // buffer para ocho caracteres 5 6 gets(buf); // lee de stdio (¡función sensible!) 7 8 printf("%s", buf); // imprime los datos almacenados en buf 9 10 return 0; // 0 como valor de retorno 11}
Esta aplicación muy simple lee de la entrada estándar una matriz de caracteres y la copia en el búfer del tipo char. El tamaño de este búfer es de ocho caracteres. Después de eso, se muestra el contenido del búfer y la aplicación se cierra.
Compilación del programa:
1user@spin ~/inzynieria $ gcc bo-simple.c -o bo-simple 2 3/tmp/ccECXQAX.o: In function `main': 4bo-simple.c:(.text+0x17): warning: the `gets' function is dangerous and should not be used. 5 6At this stage, even the compiler suggests that the gets() function is not safe.
Ejemplo de uso:
1user@spin ~/inzynieria $ ./bo-simple // inicio del programa 2 31234 // introducimos la cadena "1234" desde el teclado 4 51234 // el programa imprime el contenido del buffer 6 7user@spin ~/inzynieria $ ./bo-simple // inicio del programa 8 9123456789012 // introducimos "123456789012" 10 11123456789012 // contenido del buffer "buf" ?!?!! 12 13Fallo de segmentación // información sobre el fallo de segmentación de memoria
Logramos (des)afortunadamente ejecutar la operación defectuosa del programa y provocamos que salga de manera anormal.
Análisis del problema
El programa llama a una función que opera en el búfer de tipo char y no realiza comprobaciones para evitar que se desborde el tamaño asignado a este búfer. Como resultado, es posible almacenar intencionalmente o no más datos en el búfer, lo que provocará un error. Surge la siguiente pregunta: El buffer almacena sólo ocho caracteres, entonces ¿por qué la función printf() muestra doce? La respuesta proviene de la organización de la memoria de procesos. Cuatro caracteres que desbordaron el búfer también sobrescriben el valor almacenado en uno de los registros, que era necesario para el retorno correcto de la función. La continuidad de la memoria resultó en la impresión de los datos almacenados en esta área de la memoria.
- Ejemplo 2
1#include <stdio.h> 2#include <string.h> 3 4void doit(void) { 5 char buf[8]; 6 gets(buf); 7 printf("%s", buf); 8} 9 10int main(void) { 11 printf("So... The End...\n"); 12 doit(); 13 printf("or... maybe not?\n"); 14 return 0; 15}
Este ejemplo es análogo al primero. Además, antes y después de la función doit(), tenemos dos llamadas a la función printf().
Compilación:
1user@dojo-labs ~/owasp/buffer_overflow $ gcc example02.c -o example02 -ggdb
Advertencia:
1/tmp/cccbMjcN.o: In function `doit': 2/home/user/owasp/buffer_overflow/example02.c:8: warning: the `gets' function is dangerous and should not be used.
Ejemplo de Uso:
1user@dojo-labs ~/owasp/buffer_overflow $ ./example02
Salida:
1So... The End... 2TEST // user data on input 3TEST // print out stored user data 4or... maybe not?
El programa entre las dos llamadas printf() definidas muestra el contenido del búfer, que se llena con los datos ingresados por el usuario.
1user@dojo-labs ~/owasp/buffer_overflow $ ./example02 2 3So... The End... 4 5TEST123456789 6 7TEST123456789 8 9Segmentation fault
Debido a que se definió el tamaño del buffer (char buf[8]) y se llenó con trece caracteres de tipo char, el buffer se desbordó. Si nuestra aplicación binaria está en formato ELF, entonces podemos usar un programa objdump para analizarla y encontrar la información necesaria para explotar el error de desbordamiento del búfer. A continuación se muestra el resultado producido por objdump. A partir de esa salida podemos encontrar direcciones, donde se llama a printf() (0x80483d6 y 0x80483e7).
1user@dojo-labs ~/owasp/buffer_overflow $ objdump -d ./example02
Salida:
080483be <main>:
80483be: 8d 4c 24 04 lea 0x4(%esp),%ecx
80483c2: 83 e4 f0 and $0xfffffffff0,%esp
80483c5: ff 71 fc pushl 0xfffffffffc(%ecx)
80483c8: 55 push %ebp
80483c9: 89 e5 mov %esp,%ebp
80483cb: 51 push %ecx
80483cc: 83 ec 04 sub $0x4,%esp
80483cf: c7 04 24 bc 84 04 08 movl $0x80484bc,(%esp)
80483d6: e8 f5 f5 fe ff ff ff call 80482d0 <puts@plt>
80483db: e8 c0 f0 ff ff ff ff call 80483a0 <doit>
80483e0: c7 04 24 cd 84 04 08 movl $0x80484cd,(%esp)
80483e7: e8 e4 fe ff ff ff call 80482d0 <puts@plt>
80483ec: b8 00 00 00 00 00 00 mov $0x0,%eax
80483f1: 83 c4 04 add $0x4,%esp
80483f4: 59 pop %ecx
80483f5: 5d pop %ebp
80483f6: 8d 61 fc lea 0xfffffffffc(%ecx),%esp
80483f9: c3 ret
80483fa: 90 nop
80483fb: 90 nop
Si la segunda llamada a printf() informaría al administrador sobre el cierre de sesión del usuario (por ejemplo, sesión cerrada), entonces podemos intentar omitir este paso y finalizar sin la llamada a printf().
1user@dojo-labs ~/owasp/buffer_overflow $ perl -e 'print "A "x12 . "\xf9\x83\x04\x08"' | ./example02
Salida:
So... The End...
AAAAAAAAAAAAAAAAAAu*.
Segmentation fault
La aplicación finalizó su ejecución con fallo de segmentación, pero la segunda llamada a printf() no tuvo cabida. Algunas palabras de explicación:
perl -e 'print “A”x12 .”\xf9\x83\x04\x08”' - imprimirá doce caracteres “A” y luego cuatro caracteres, que de hecho son una dirección de la instrucción que queremos ejecutar. ¿Por qué doce?
18 // Size of buf (char buf[8]) 2 3+ 4 // Four additional bytes for overwriting stack stack frame pointer 4 5---- 6 712
Análisis del problema:
La cuestión es la misma que en el primer ejemplo. No hay control sobre el tamaño del buffer copiado en el previamente declarado. En este ejemplo, sobrescribimos el registro EIP con la dirección 0x080483f9, que de hecho es una llamada a ret en la última fase de la ejecución del programa.
¿Cómo utilizar los errores de desbordamiento del búfer de una forma diferente?
Generalmente, la explotación de estos errores puede conducir a:
- aplicación DoS
- reordenar la ejecución de funciones
- ejecución de código (si podemos inyectar el código shell, descrito en el documento separado)
¿Cómo se cometen los errores de desbordamiento del búfer?
Este tipo de errores son muy fáciles de cometer. Durante años fueron la pesadilla de un programador. El problema radica en las funciones nativas de C, a las que no les importa realizar comprobaciones adecuadas de la longitud del búfer. A continuación se muestra la lista de dichas funciones y, si existen, sus equivalentes seguros:
Claro, aquí está la traducción al español:
gets()->fgets()- leer caracteresstrcpy()->strncpy()- copiar el contenido del bufferstrcat()->strncat()- concatenación de buffersprintf()->snprintf()- llenar el búfer con datos de diferentes tipos(f)scanf()- leer desde STDINgetwd()- volver al directorio de trabajorealpath()- devolver la ruta absoluta (completa)
Utilice funciones equivalentes seguras, que verifiquen la longitud de los buffers, siempre que sea posible. A saber:
- gets() -> fgets()
- strcpy() -> strncpy()
- strcat() -> strncat()
- sprintf() -> snprintf()
Aquellas funciones que no tienen equivalentes seguros deben reescribirse implementando comprobaciones seguras. El tiempo dedicado a ello se beneficiará en el futuro. Recuerda que tienes que hacerlo sólo una vez. Utilice compiladores, que sean capaces de identificar funciones inseguras, errores lógicos y comprobar si la memoria se sobrescribe cuando y donde no debería estar.
Explotaciones de aplicaciones web: cómo los piratas informáticos aprovechan las vulnerabilidades de desbordamiento del búfer
Esta es una aplicación web deliberadamente vulnerable que se utiliza con fines educativos y de prueba. Seleccione Iniciar sesión e inicie sesión en la aplicación utilizando las siguientes credenciales:
Nombre de usuario → admin
Contraseña → admin
Haga clic en el enlace Feedback junto a la barra de búsqueda en la esquina superior derecha.
La aplicación no realiza una verificación de longitud y es vulnerable a ataques de desbordamiento.
Si un atacante envía más datos de los que el búfer puede contener, el exceso de datos se desbordará hacia áreas de memoria adyacentes, sobrescribiendo potencialmente datos críticos o el código de la aplicación. Esto puede provocar un comportamiento impredecible y potencialmente malicioso.
Scripting para Red Team.
LOLBAS: colección de scripts para ataques en Red Team
Distintos investigadores y hackers se han propuesto construir una lista de LOLBins, programas legítimos de los cuales se puede abusar para evitar la seguridad y evadir la detección. Estos programas pueden serr utilizados por equipos de Red Team o directamente por atacantes en malware, APTs y en situaciones de escalamiento de privilegios y ataques laterales.
La confianza es uno de los pilares clave en los que se basa la seguridad de la información. En última instancia, lo que determina quién tiene acceso a qué, qué aplicaciones pueden ejecutarse y cuáles no. ¿Pero qué pasa cuando se abusa de esa confianza? Por ejemplo, cuando aplicaciones autorizadas y confiables son utilizadas por atacantes.
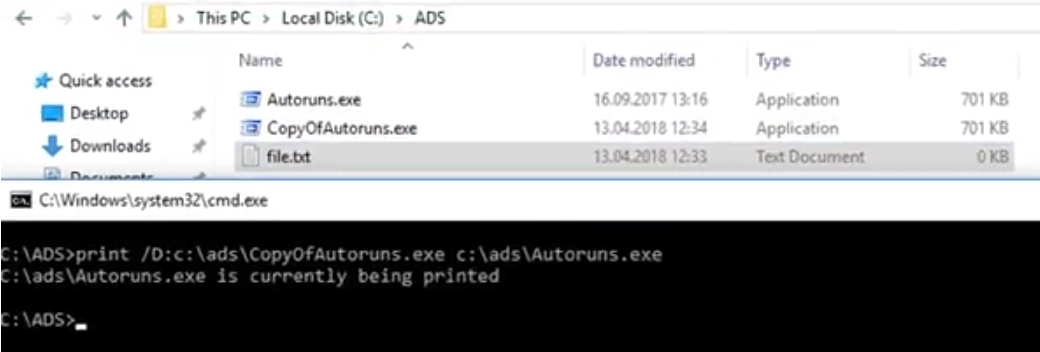
Los LOLBins son un buen ejemplo de la explotación de confianza: son binarios "confiables" que un atacante puede usar para realizar acciones distintas de aquellas para las que originalmente fueron diseñados. Como tal, los LOLBins hacen posible que los atacantes eviten las contramedidas defensivas, como la inclusión en la lista blanca de aplicaciones, el monitoreo de seguridad y el software antivirus con una menor posibilidad de ser detectados. Un ejemplo, se puede usar el comando print.exe para copiar un archivo a un Alternate Data Stream (ADS) y luego ejecutarlo.
LOLBAS ("Living Off the Land Binaries and Scripts").
Actualmente, hay más de 130 LOLBins, LOLLibs y LOLScripts en la lista, que van desde la herramienta de transferencia de datos legítima de Microsoft Bitsadmin.exe hasta print.exe. La lista incluye programas que han documentado un potencial de abuso, así como una variedad de programas que ya se han convertido en herramientas favoritas para recuperar cargas útiles de malware durante ataques del mundo real, incluidos mshta.exe, certutil.exe y regsvr32.exe.
Tener una buena documentación sobre estos binarios y scripts puede ayudar a todos a prevenir ataques al bloquear activamente su ejecución. Si sabes que algo puede ser usado para el mal, hace que el trabajo sea mucho más fácil cuando buscas ataques e intentas prevenirlos. Después de todo, los actores de amenaza de persistencia avanzada (APT) ya están usando estos binarios / scripts como parte de sus ataques. Por lo tanto, debemos profundizar en todos los archivos y descubrir formas inteligentes en que podamos usar esta lista antes de que lo hagan los atacantes.
LOLBAS funciona como una lista dinámica mantenida por la comunidad. Cualquier persona interesada en realizar una investigación de seguridad para enviar nuevos LOLBins es alentada a hacerlo y ser reconocida por ello. La lista actual es solo el comienzo y se espera poder proporcionar una lista de búsqueda en un formato de base de datos para el servicio, asignarla al marco MITRE ATT & CK y agregar más datos en cada registro de LOLBin y LOLScript, incluida la información sobre su detección y las técnicas de bloqueo relevantes.
GTFOBins
GTFOBins es una lista inspirada en LOBAS pero con binarios de Unix/Linux que pueden ser explotados por un atacantes para saltear restricciones de seguridad locales.
Offensive-PowerShell
Offensive-PowerShell es un repositorio de Github contiene un recopilatorio de scripts en Powershell para operaciones ofensivas relacionadas con tareas de Red Teaming. Se describen cómo funciona cada uno y dan un pequeño tutorial en inglés sobre cómo usarlos, además de decir con qué versiones de Windows son compatibles.
Automatizando el Reconocimiento de un Red Team con Discover Scripts
Cuando hablamos de Red Team el alcance del mismo, no sólo abarca a las tecnologías sino también a las personas y procesos. Otra cosa que ya hemos mencionado más de una vez es que, a diferencia de un pentest tradicional, el cual mucho más acotado en tiempo y alcance, un servicio de red team justamente es muchísimo más amplio tanto en su ventana de tiempo de ejecución como en su alcance ya que, entre otras cosas se trata de generar la mayor cantidad de escenarios posibles o incluso replicar campañas de APT conocidas, lo cual brinda como resultado un resultado mucho más holístico en relación a la postura de seguridad de una determinada compañía o entidad.
Aclarado el contexto, está claro que la fase de reconocimiento en el mundo del Red Team, a diferencia justamente de un pentest tradicional, es de vital importancia. Justamente, cuando hablamos de reconocimiento, hablamos de OSINT en todos sus aspectos o lo que se suele llamar tradicionalmente como information gathering pasivo y activo. Dado que justamente en un ejercicio de red team se suele modelar con muchísimo más tiempo un escenario de ataque.
Mientras más tiempo le dediquemos a esta fase más van a ser los vectores de ataque que se puedan utilizar para realizar un ataque exitoso, desde bucket de AWS, servicios que no necesariamente deberían estar expuestos (RDP por ejemplo), paneles de gestión web, posibles cuentas de github en donde los desarrolladores de la compañía guardan código de la misma, etc. En un ejercicio de Red Team todo y absolutamente todo lo que se encuentre puede ser un expuesto a vulnerar.
Veremos una herramienta de tipo «all in one» que no suele realmente ser muy conocida pero que lleva varios años La herramienta se llama «Discover Scripts» de Lee Baird @discoverscripts (https://github.com/leebaird/discover) y antes era conocida cómo Backtrack Scripts, se imaginarán porque la misma era parte de la suite de herramientas de Backtrack Kali Linux antes de convertirse en Kali Linux.
Esta herramienta o conjunto de scripts, yo la uso mucho en lo particular y lo interesante es que también se puede usarse para otras cuestiones no tan relativas a OSINT sino que a través de la misma se pueden disparar otras tools como Recon-NG o por ejemplo Nikto para un escaneo web.
Discover Scripts, cómo su nombre indica, es un conjunto de scripts que disparan acciones o herramientas. Utiliza herramientas cómo «dnsrecon, goofile, goog-mail, goohost, theharvester, metasploit, urlcrazy, whois, wikto y varias otras.
Instalación
Para instalarla solo deberemos clonar el repositorio desde su sitio oficial git clone.

Una vez finalizada la instalación deberemos movernos al directorio /opt/discover que es dónde se instala por default. Lo primero que deberemos hacer ahora es correr el script bash de actualización de la herramienta el cual ./update.sh.

Al disparar el script la herramienta empezará a instalar no solamente los componentes necesarios, sino que, además, la misma instalará muchas otras herramientas de las que se vale para hacer las diferentes búsquedas que hace e incluso herramientas ofensivas como impacket y muchas otras. El proceso de instalación lleva un tiempo largo con lo cual sugerimos un poco de paciencia e ir siguiendo el paso a paso de la instalación con un café.
Ejecución de la herramienta
Una vez finalizada 100% la instalación y actualización de todos los componentes, y estándo parados en el directorio de la misma ya podemos empezar a utilizar la herramienta, para hacerlo sólo debemos correr el script ./discover.sh con el comando sudo por delante, excepto que estemos trabajando con la cuenta de root en forma directa.

Al disparar el script nos aparecerá la siguiente pantalla:
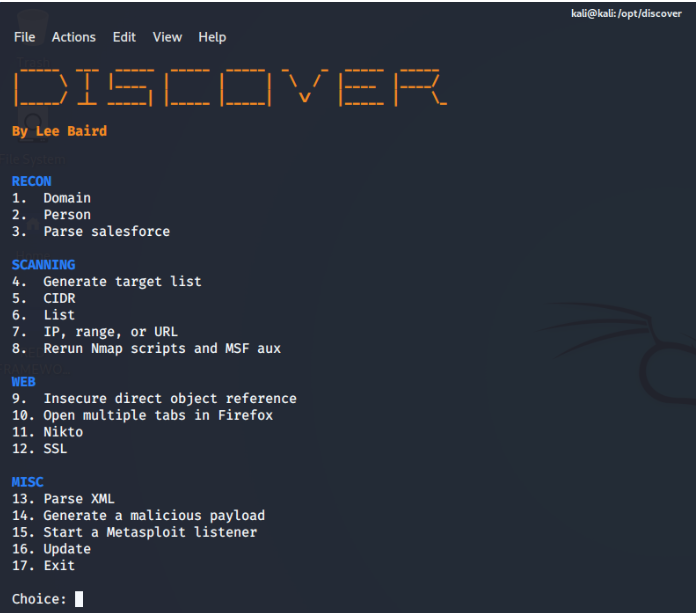
Cómo podemos ver la herramienta tiene varias opciones que no solamente están limitadas al «Reconocimiento» sino que puede invocar escaneos de puertos (port scanning) con nmap o incluso escaneos web con Nikto, por sólo mencionar algunas de las opciones.
Recomendados mirar el sitio web de github de Lee Baird para ver la documentación del uso ya que es bastante extensivo todo lo que se puede realizar con la herramienta. En nuestro caso, y dado que estamos hablando de «Reconocimiento» en el marco de un Red Team Engagement, trabajaremos solamente con la opción de «RECON».
Entonces vamos a marcar dentro de RECON la opción 1 llamada Domain, para eso solo tipeamos el número 1 en la consola y le damos enter y nos aparecerá el siguiente menú que se observa:
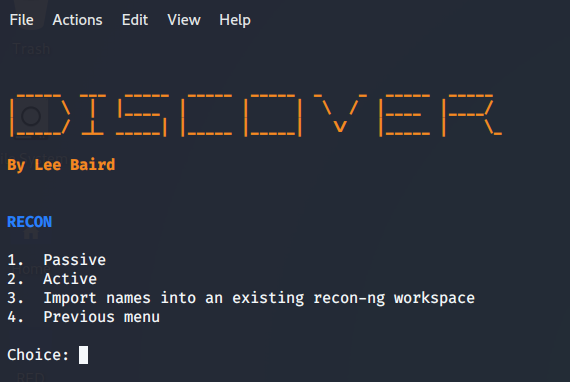
En este caso, vamos a trabajar con la opción 1 llamada «Passive» dado que queremos recolectar la mayor cantidad de información en forma 100% pasiva sin que la actividad en sí, pueda ser detectada de alguna forma u otra.
NOTA: Si tipeamos la opción «Active» la búsqueda utilizará módulos de herramientas cómo dnsrecon, WAF00W, traceroute, Whatweb, and recon-ng, los cuales no son pasivos y podrían detectar nuestra actividad y que nuestra IP sea baneada. Vamos a tomar un dominio válido ya que, en principio, no estamos haciendo absolutamente nada más que recolectar información. Para ellos voy a usar el dominio de https://www.nintendo.com/.
Para ello entonces, luego de seleccionar la opción 1 de «Passive» como ya dijimos antes, nos va a pedir que ingresemos el nombre de la compañía (Esto sirve para el nombre del reporte que la herramienta va a crear una vez que termine) y por otro lado el nombre del domino, el cual deberá ingresarse con el formato «dominio.com» es decir sin www ni http. En nuestro caso «Nintendo.com».
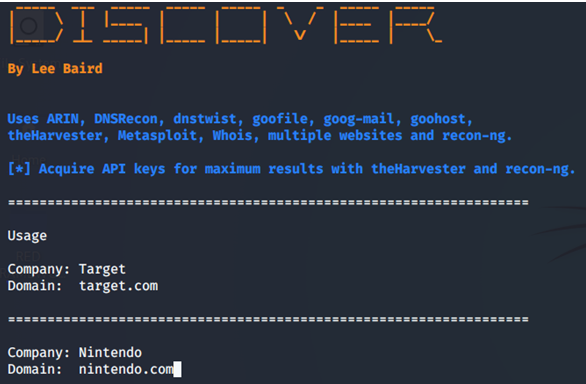
Si prestamos atención podemos ver la imagen que la herramienta nos dice que va a utilizar entre otras herramientas ARIN, DNSRecon, dnstwist, TheHarvester, recon-ng, y varias más e inclusive nos indica que si queremos generar APIs para maximizar el resultado lo hagamos, lo cual recomendamos tanto para BING, Google CSE, Shodan, Censys, etc.
Las APIs que hayamos generado se pueden cargar en las diferentes herramientas que se utilizan, en este caso por sobre todo recon-ng y theharvester, con lo cual las APIs se cargarían de la siguiente manera:
En recon-ng se puede usar el comando «show keys» y luego ingresar las APIs con el comando «keys add», ejemplo: «keys add bing_api
».
Una vez que le damos «enter» la herramienta empieza a correr con lo cual acá recomendamos otro cafecito. Veremos que arranca corriendo y haciendo diferentes querys a través de variadas tools:
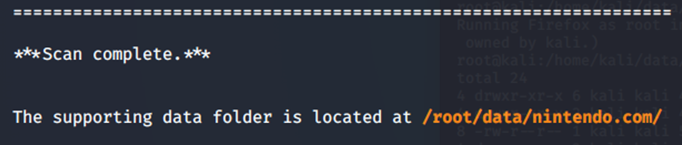
Una vez que la herramienta termina de trabajar nos va a decir «Scan Complete» y nos va a mostrar en que ruta se guarda el archivo, en este caso dentro de /root/data/Nintendo.com que es el dominio que especificamos.
Desde una consola como root entonces disparamos el Firefox al archivo index.html generado dentro de /root/data/Nintendo.com/ y veremos en el navegador lo siguiente:
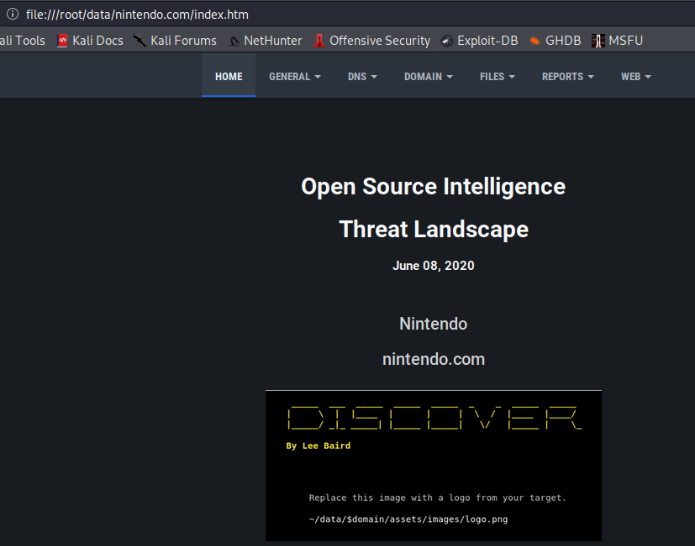
Podemos observar en la pantalla que se nos generan varios tabs en dónde tenemos el de «Home», «General», «DNS», «Domain», «File», «Reports» y «Web». En general vamos a poder encontrar listado de usuarios y correos electrónicos que después se puede usar dicho listado para crear un diccionario customizado aunque hay que validar mucha de esta información.
Sugerimos que esto se haga directamente buscando información en el sitio oficial de la empresa u entidad que se esté mirando en ese momento como a través de técnicas de scrapping por ejemplo de Linkedin de los usuarios de dicha compañía (Cosa que veremos más adelante en otra entrada). En el caso de DNS es dónde empezamos a ver los mapas y registros de DNS perteneciente a la empresa o entidad, cómo por ejemplo se puede ver a continuación.
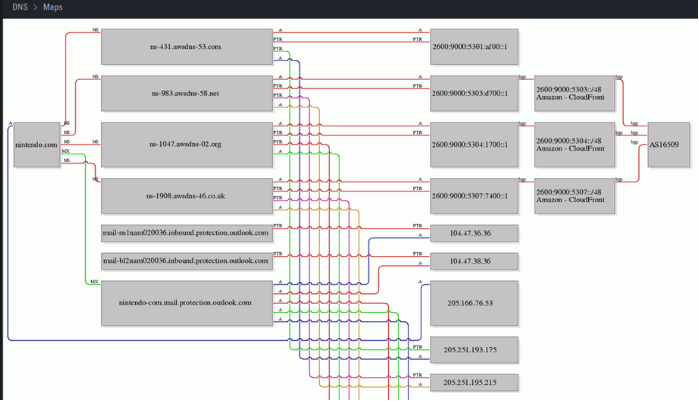
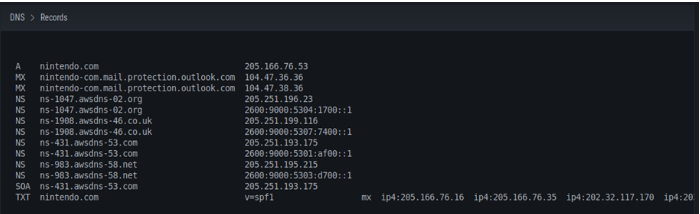
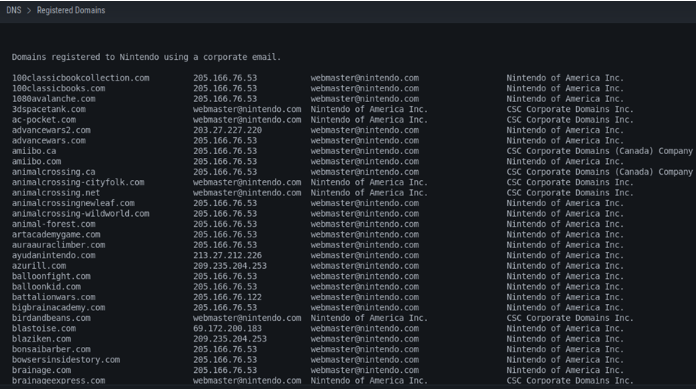
También podremos ver dentro de este contexto otros dominios DNS registrados por la compañía, en este caso utilizados como mail corporativo.
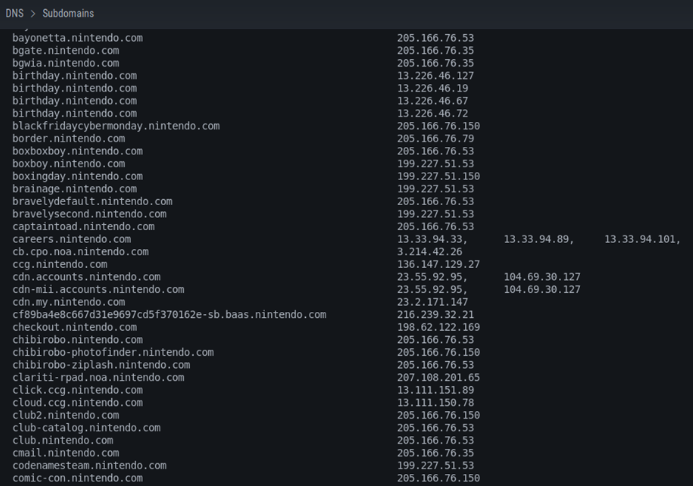
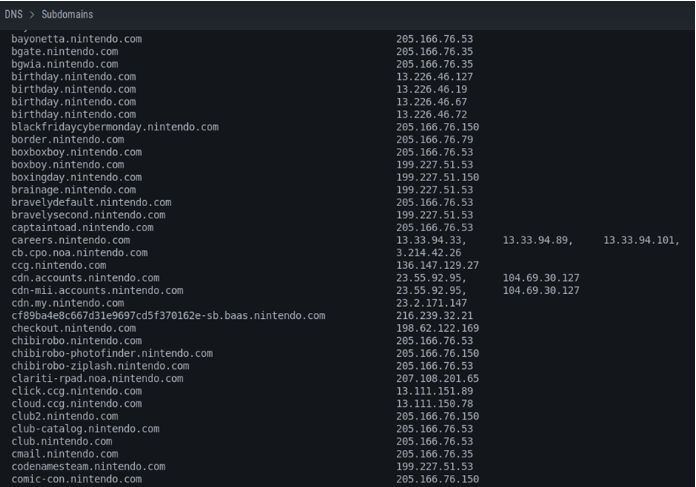
También los sub dominios, que en este caso particular podemos ver que son muchos dados que es una empresa o compañía extremadamente grande.
En el tab de «Files» podemos ver que la herramienta nos muestra todos los archivos que están públicos, en este caso seleccionamos la opción PDF de entre todos los que nos brinda. Esto es extremadamente útil ya que podríamos complementariamente bajar muchos de estos archivos con herramientas cómo Foca o metagoofil para poder extraer adicionalmente otros datos de utilidad a través de la metadata de los mismos.
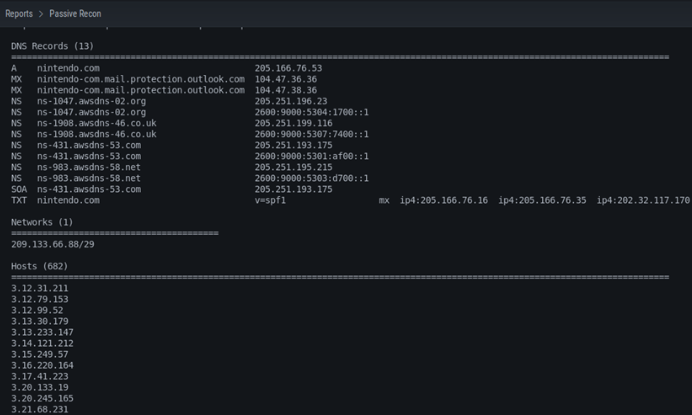
Por último (Al menos en lo que este post se refiere) podemos ver también que, cuando nos dirigimos al tab «Reports» se nos despliegan muchas dos opciones de las cuales una es la de «Active Recon» y la segunda la de «Passive Recon». En este caso y dado que desde el principio sólo corrimos un Passive Recon para la opción «Domain», está será la opción que se seleccionaremos. Al hacerlo veremos que nos muestra un resúmen pormenorizado de todo lo que encontró en una forma súper útil para seguir.
Conclusiones
Esta herramienta junto con el uso de recon-ng en forma automatizada, yo la uso mucho para recolectar información. Cómo toda herramienta de «botón gordo» ayuda mucho a automatizar y recolectar mucha información en un lapso mucho menor que la búsqueda meramente manual, no obstánte hay que recordar que:
- Muchos de los datos se deben Re validar manualmente
- Que la parte de datos de casillas de correo y de personas conviene sacarlos por otro medio o por algunos módulos específicos de recon-ng que ya veremos más adelante o mismo por scrapping.
- Que se debe utilizar si o si tanto en recon-ng cómo en la herramienta de «TheHarvester» las APIs que ya previamente tengamos registradas (Shodan, Censys, Bing, GoogleCSE, Virustotal, etc.) ya que va a ser mucho más rica la búsqueda que nos genere la herramienta.
Recordemos además que la herramienta puede automatizar escaneos activos, automatizar el uso de metasploit a través de módulos que invoca, automatizar escaneos web con nikto y muchas cosas más ya que, además de la automatización de muchas de las herramientas que ya mencionamos al principio también en el caso de su uso en Kali Linux utiliza y automatiza el «Penetration Tester Framework» (PTF).
Espero que les haya gustado la nota. Happy hacking!