Beautiful Soup
Python
Web Scraping con Beautiful Soap
Web Scraping¶
Web Scraping se conoce como uno de los métodos más importantes para recuperar contenidos y datos de un sitio web automáticamente utilizando software. Esta información más tarde se puede utilizar para añadir contenido en una base de datos, exportar información a tipos de documentos estructurados, etcétera.
El listado de lo que podemos "scrapear" en la web es amplio, pero incluye:
- Redes sociales (Facebook, Twitter...).
- Motores de búsqueda (Google, Bing...).
- Páginas corporativas: tiendas online, servicios, de información empresarial, etcétera.
- Páginas gubernamentales oficiales y de noticias.
Existen dos formas de "scrapear", dependiendo de lo que queramos obtener de Internet:
- Obtener archivos/documentos.
- Obtener información.
La diferencia entre el primer y segundo punto es que un archivo contiene información, pero no está descrito en la página web. Con el segundo punto lo que buscamos es extraer párrafos, títulos, cantidades, importes, etcétera inmersos en la web.
Como es evidente, utilizaremos Python para obtener contenido de Internet. Manteniendo el uso del mismo lenguaje aseguramos que todo el proceso de ETL (Extract, Transform, Load) quede integrado aumentando legibilidad y mantenibilidad.
1. Obtener archivos/documentos¶
En Python, el paquete requests permite interactuar con URIs HTTP y que posibilita, por ejemplo, descargar recursos y archivos alojados en alguna página web. La función que permite hacer esto es get y, en nuestro caso, permitiría descargar cierta información y transformarla, por ejemplo, en un DataFrame de Pandas.
Paso 1. Encontrar el recurso a descargar¶
En este caso estamos interesados en descargar información sobre los ingresos en Estados Unidos. Para ello, dado que no disponemos de información en nuestra base de datos (está vacía) buscamos recursos en Internet. Localizamos una fuente que nos podría permitir desarrollar un modelo predictivo, y accedemos a ella:
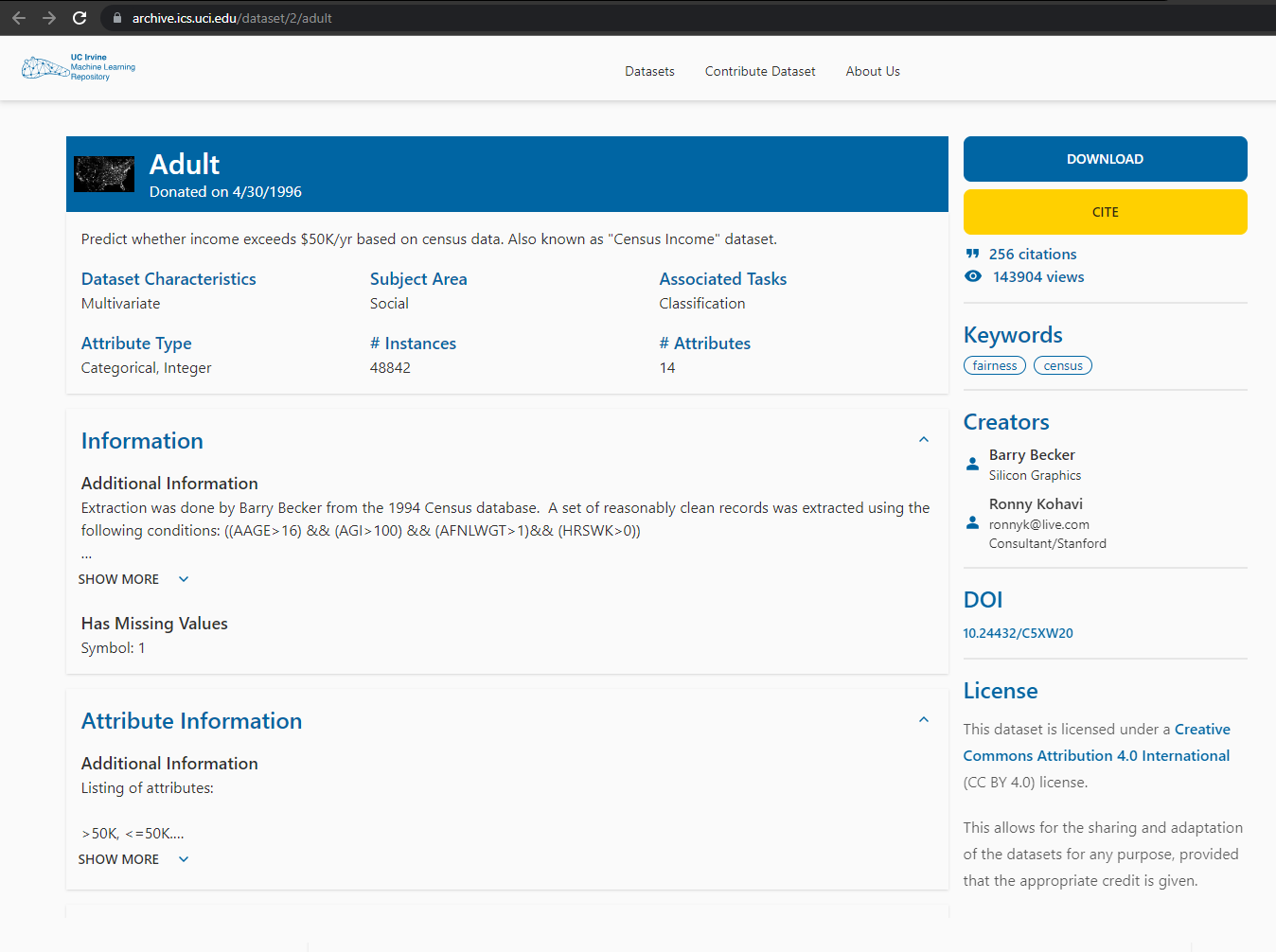
Paso 2. Localizar el punto de descarga del recurso¶
El siguiente paso es localizar desde qué dirección podremos descargar el recurso. El UCI Repository proporciona una interfaz muy intuitiva para descargar recursos. Copiando la dirección del botón Download podremos obtener fácilmente el punto de descarga. Sin embargo, dependiendo de la página web, a veces obtener este enlace es lo más complicado de todo el proceso.
Tras analizar la web, obtenemos que el enlace de descarga es el siguiente: https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data.
Paso 3. Programar la descarga del fichero¶
Lo último que queda antes de poder trabajar con la información es descargarla. Para ello utilizaremos el paquete requests, ya que proporciona un mecanismo muy sencillo de utilizar:
import requests
# Seleccionar el recurso a descargar
resource_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
# Petición para descargar el fichero de Internet
response = requests.get(resource_url)
# Si la petición se ha ejecutado correctamente (código 200), entonces el fichero se ha podido descargar
if response:
# Se almacena el archivo en el directorio actual para usarlo más tarde
with open("adult.csv", "wb") as dataset:
dataset.write(response.content)
El resultado es un fichero totalmente utilizable en nuestro directorio y que proviene de Internet, totalmente utilizable para el resto de pasos a realizar para entrenar nuestro modelo de Machine Learning.
Ahora, podríamos leerlo con Pandas y crear un DataFrame a partir del fichero.
2. Obtener información¶
Obtener información es un proceso más tedioso que el anterior, porque necesitamos profundizar en la estructura HTML de los documentos para obtener esa información. Existen muchas formas de llevar a cabo este proceso, así como muchas herramientas y paquetes en Python que nos posibilitan hacerlo. requests y BeautifulSoup son una buena combinación para llevar a cabo esta tarea satisfactoriamente y de la manera más sencilla.
Paso 1. Encontrar el contenido a obtener¶
En este caso, estamos interesados en obtener la información sobre el piso más barato que se puede adquirir en Guardamar del Segura, una ciudad costera al sur de Alicante. Dado que no tenemos información al respecto, decidimos buscarla en un portal inmobiliario como Inmobiliaria CGI. El primer paso es acceder a la web, filtrar por la ciudad y ordenar los resultados en la web:
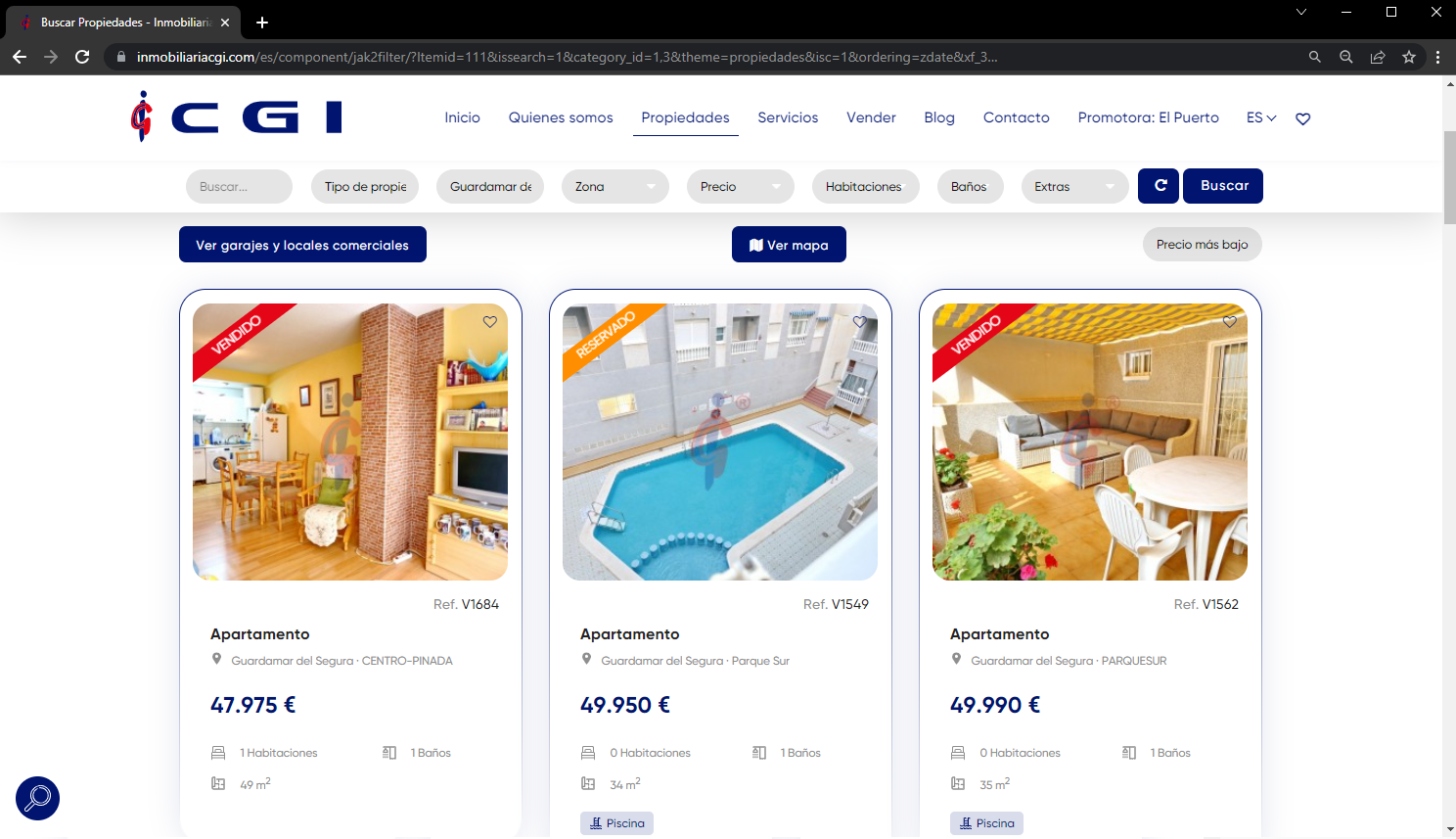
Después de filtrar el contenido y prepararlo (esto se hace así con un ejemplo sencillo, pero normalmente se filtran y ordenan resultados a nivel código), obtenemos la URL del contenido general, sobre el que obtendremos el importe total: https://inmobiliariacgi.com/es/component/jak2filter/?Itemid=111&issearch=1&category_id=1,3&theme=propiedades&isc=1&ordering=zdate&xf_3=2&orders[xf5]=xf5
Paso 2. Descargar todo el contenido HTML de la URL¶
A continuación debemos descargar el contenido de la página anterior. Para ello utilizamos, por un lado, la librería requests para descargar el HTML en formato de texto plano, y BeautifulSoup para generar el árbol de elementos y poder realizar consultas para obtener la información que queramos obtener.
import requests
import time
from bs4 import BeautifulSoup
# Seleccionar el recurso a descargar
resource_url = "https://inmobiliariacgi.com/es/component/jak2filter/?Itemid=111&issearch=1&category_id=1,3&theme=propiedades&isc=1&ordering=zdate&xf_3=2&orders[xf5]=xf5"
# Petición para descargar el fichero de Internet
response = requests.get(resource_url, time.sleep(10))
# Si la petición se ha ejecutado correctamente (código 200), entonces el contenido HTML de la página se ha podido descargar
if response:
# Transformamos el HTML plano en un HTML real (estructurado y anidado, con forma de árbol)
soup = BeautifulSoup(response.text, 'html')
soup
Como se puede apreciar, el objeto soup contiene el HTML y a partir de él se pueden hacer ciertas consultas para obtener la información. En este caso buscamos obtener el importe (marcado en rojo en la imagen). Para poder llevar a cabo una extracción satisfactoria, debemos buscar el elemento en el HTML de la página web antes de comenzar a trabajar con el objeto soup. Para ello, nos servimos de las herramientas de desarrollador de nuestro navegador:
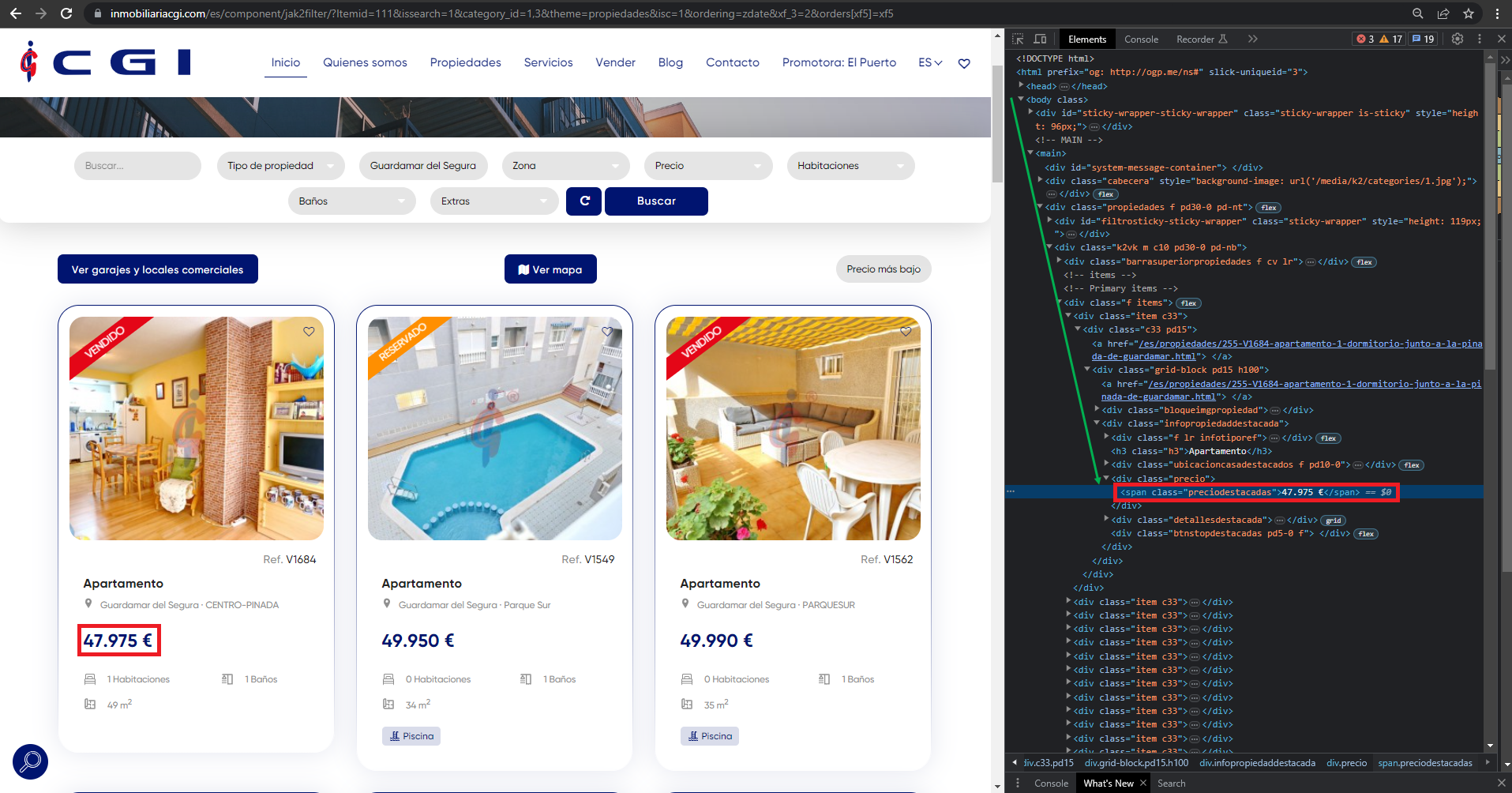
Buscando el elemento lo encontramos encerrado dentro del siguiente div:
<div class="precio">
<span class="preciodestacadas">47.975 €</span>
</div>
Además, como se aprecia en la flecha verde, este elemento anterior se encuentra encerrado dentro de una jerarquía que desencadena el elemento body del HTML. Existen tres formas de extraer el valor que queremos:
- Filtro por jerarquía.
- Filtro por nombre de etiqueta.
- Filtro por atributos.
Filtro por jerarquía¶
Este tipo de filtro requiere de recorrer todo el árbol jerárquico del HTML hasta dar con el elemento. Sabemos que tras haber encontrado el elemento, observando la imagen anterior, la jerarquía es la siguiente:
body > main > div > div > div > div > div > div > div > div > span
Siendo el elemento span el que contiene el importe que queremos extraer. Sin embargo, esta forma de extraer información es muy poco eficiente, no es mantenible (pequeños cambios en la página web pueden afectar mucho a la extracción) y requiere de tiempos de desarrollo muy elevados, ya que hay páginas web que cuentan con una jerarquización todavía más compleja.
Filtro por nombre de etiqueta¶
Es uno de los filtros más comunes y utilizados. Es el filtro más básico, ya que consiste en pasar el nombre de la etiqueta a buscar en la función de búsqueda, para seleccionar después el deseado.
En nuestro ejemplo, estamos buscando un elemento span, así que no tenemos más que encontrar todos los que haya en el documento HTML y procesarlos hasta encontrar el deseado.
import re
# Obtener todos los elementos de tipo 'span' del documento HTML
spans = soup.find_all("span")
# Iteramos por cada uno de los resultados para encontrar el elemento que contiene el importe determinado. Como el importe que estamos buscando es el primero de todos, lo buscamos (por ejemplo, con una expresión regular) y cuando lo encontramos, imprimimos su valor
for span in spans:
amount = re.search(r'\d+\.\d+', span.text)
if amount:
break
print(f"El importe de la casa de Guardamar del Segura más barata es {amount}")
Sin embargo, esta metodología es poco útil si, por ejemplo, hubiese otro importe encima que no estuviese relacionado con lo que queremos extraer. Además, es muy poco eficiente en tiempo, ya que requiere que se analicen todos los elementos de la web hasta encontrar el apropiado. Esto provoca que sea una mala alternativa para entornos en tiempo real, grandes análisis, etcétera.
Filtro por atributos¶
Podemos utilizar otro mecanismo para seleccionar elementos de nuestro árbol HTML: identificadores y clases. De esta forma, podemos localizar rápidamente el elemento a través de su clase. Así, si el div que contenía el span era el siguiente:
<div class="precio">
<span class="preciodestacadas">47.975 €</span>
</div>
Entonces, usando la clase preciodestacadas podríamos filtrar rápidamente este elemento y obtenerlo.
amounts = soup.find_all("span", class_="preciodestacadas")
print(f"El importe de la casa de Guardamar del Segura más barata es {amounts[0].text}")
Para obtener el texto de un elemento span, debemos utilizar el atributo text, tal y como se aprecia en el código anterior.