GitHub
como usa GIT
git
Cómo usar GIT: Sistema de control de versiones
☝ También hemos preparado un tutorial interactivo sobre GIT. Haga clic aquí para tomarlo!
¡GIT es una necesidad!
GIT es una gran tecnología, tómate el tiempo para aprenderla. NO lo postergues porque no puedes evitarlo. Lo usarás todos los días, varias veces al día. Así que es mejor que aprendas y te sientas cómodo con eso.
GIT es más que un "conjunto de comandos" que tienes que aprender. A lo largo de los años, hemos aprendido que la mejor manera de enseñar GIT es mediante la comprensión de los conceptos y el significado de la tecnología, en lugar de dar una lista de los comandos que se deben usar.
¿Por qué molestarse en usar GIT?
Ser el único desarrollador en un proyecto es una utopía. Normalmente, colaboras con otros desarrolladores y, sin GIT, eso se convierte en un gran problema. Es por eso que necesitamos un repositorio de información para centralizar y gestionar los cambios. Con un repositorio nos referimos a lo siguiente:
- Si dos desarrolladores trabajan en la misma página (archivo), GIT comparará ambas versiones y las intentará fusionar en una nueva.
- Descargar e integrar el código de otra persona (o cualquier otro código) en su proyecto sin mayores problemas y hacerlo de forma automática.
- Si ambos desarrolladores actualizaron exactamente el mismo código, GIT le pedirá al último desarrollador que subió el código que resuelva cualquier posible conflicto.
- El código está respaldado todo el tiempo con la última versión como principal.
- Cada desarrollador tiene su propia versión del proyecto a nivel local durante el tiempo que deseen.
- Permite trabajar en equipos remotos.
El propósito de GIT es interactuar con el repositorio de un proyecto (un conjunto de archivos) a medida que cambian con el tiempo.
Arquitectura de un repositorio
Un repositorio GIT se compone de lo siguiente:
- Un conjunto de objetos de confirmación (commit object).
- Un conjunto de referencias que apuntan a objetos de confirmación, comúnmente llamadas cabeceras (heads, en inglés).
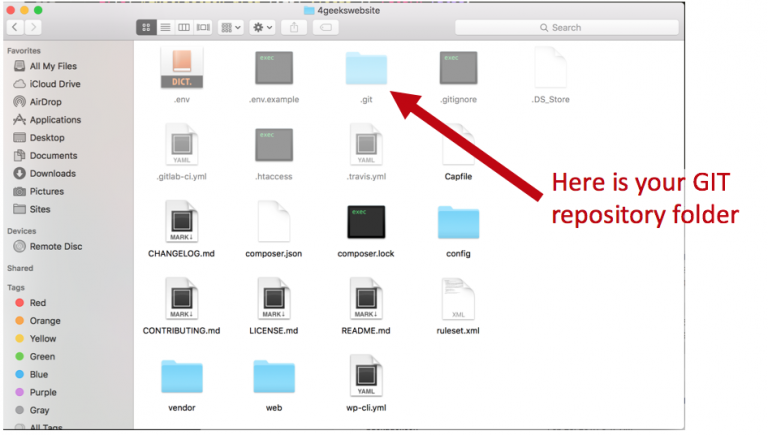
El repositorio de GIT se almacena dentro del mismo directorio que se encuentra el proyecto en un subdirectorio -oculto- llamado .git:
- Solo hay un directorio .git - ubicado en el directorio raíz del proyecto.
- El repositorio se almacena dentro del proyecto.
Commit Objects
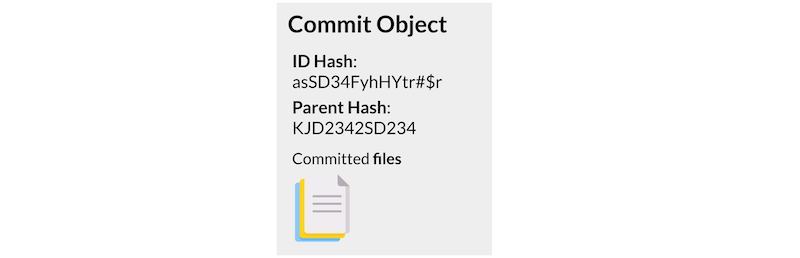
Un commit object contiene tres cosas:
- Un conjunto de archivos, que refleja el estado de un proyecto en un momento dado en el tiempo.
- Referencias al commit object padre.
- Un nombre SHA1: es una cadena de 40 caracteres que identifica de forma única el commit object. El nombre se compone de un conjunto de aspectos relevantes del commit; de esta manera, los commit idénticos siempre tendrán el mismo nombre.
Los commit object padre son aquellos commits que vinieron primero. Generalmente un commit object tendrá un commit padre. En general, uno toma un proyecto en un estado determinado (commit), realiza algunos cambios y guarda el nuevo estado (commit) del proyecto.
Al principio, un proyecto siempre tiene un commit object sin padre. Este es el primer commit que se realiza en el repositorio del proyecto.
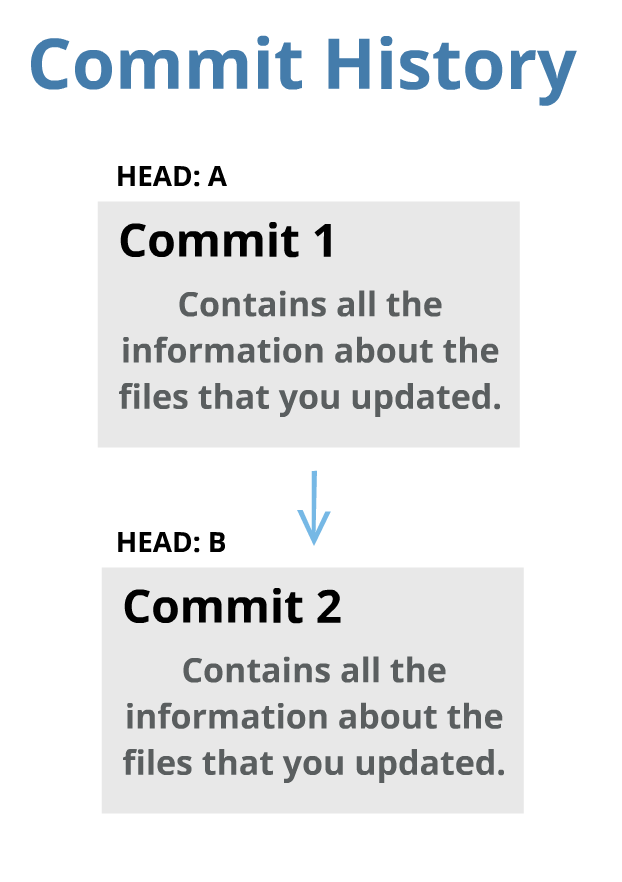
Un Head es una Lista de Commits
Los heads de un repositorio son como el "historial de revisión de un proyecto". Un historial de revisión es una lista de commit objects que contienen todos los cambios que tú y los demás miembros de tu equipo han realizado en los archivos del proyecto.
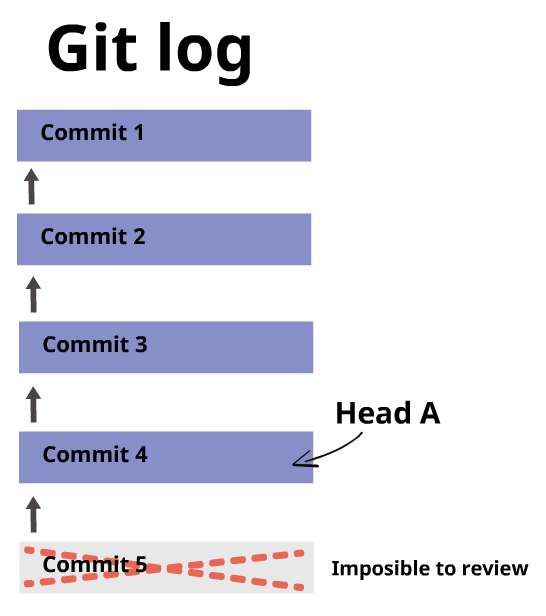
Cada vez que hagas un nuevo commit, el head se moverá a ese nuevo commit. De esta manera tú puedes tener acceso a todo el historial de commits del proyecto.
Puedes mover el head si quieres. No necesariamente tiene que ser siempre el último commit, pero debes recordar que solo puedes revisar los commits que vinieron antes del commit al que apunta el head. No se pueden revisar los commits hechos después del commit al que apunta el head.
Puedes tener varios Heads (Ramas o Branches)
Los Heads marcan el comienzo de un historial de revisión. En GIT, un historial de revisión se llama "branch" o "rama", y es posible tener varios historiales de revisión.
Por defecto, cada repositorio tiene una rama o branch llamada main (anteriormente se denominaba master), con su HEAD correspondiente que apunta al último commit de esa rama.
Ejemplo: Digamos que estás comenzando a desarrollar la característica/funcionalidad de "inicio de sesión" de un sitio web. Puedes crear una nueva "rama" del repositorio llamada "inicio de sesión", para que sus commits no formen parte del historial de revisión principal del proyecto. Una vez que te sientas cómodo con tu código, puedes fusionar tu rama y eliminar su head. Esto restablecerá el HEAD principal de la rama maestra (master Branch) al último commit realizado, y agregará tu nuevo código a la rama principal (master) del repositorio.
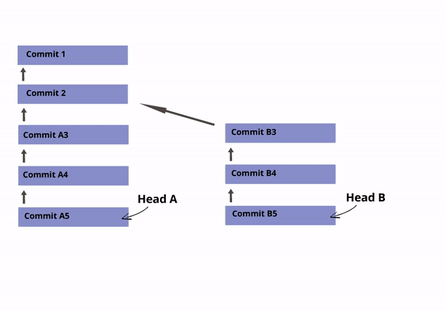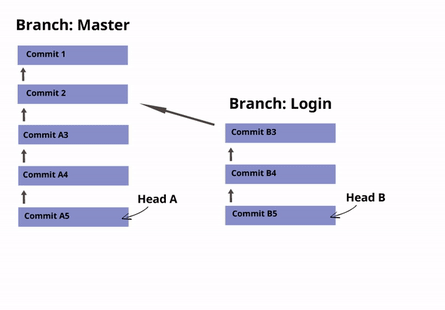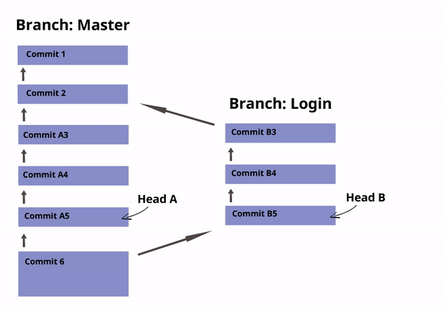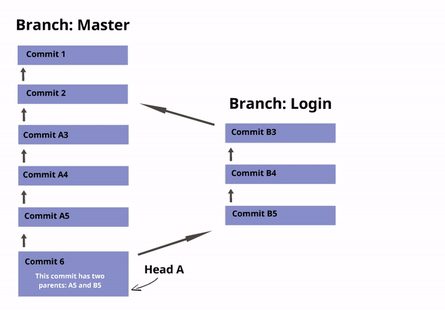
☝ Nota sobre la terminología: Los términos "branch" y "head" son casi sinónimos en GIT. Cada branch (rama) está representada por un head, y cada head representa una rama. A veces, "rama" se usará para referirse a un head y el historial completo de commits que preceden a ese head, mientras que "head" se usará para referirse exclusivamente a un solo commit object (el commit más reciente en la rama).
Comenzando un Nuevo Repo git init
Puedes crear un nuevo repositorio cuando lo desees durante el proyecto, ¡no tiene que ser al principio! Lo único esencial para hacer esto es que el proyecto no tenga otro repositorio ya creado.
1git init
Esto creará un directorio .git en el directorio del proyecto. Asegúrate de que la carpeta se haya creado correctamente (puedes ejecutar el comando ls -a para leer el contenido del directorio en la línea de comandos).
Confirmando cambios en el repositorio
Después de realizar algunos cambios en los archivos del proyecto, es posible que desees guardar/enviar esos cambios al repositorio. Esto se llama "commit".
Para crear un commit, tendrás que hacer dos cosas:
-
Indícale a GIT qué archivos incluir en el commit, con
git add .. Si un archivo no ha cambiado desde el commit anterior (el commit "principal"), GIT lo incluirá automáticamente en el commit que estás a punto de realizar. Solo deberás agregar los archivos que hayas creado o modificado recientemente. Ten en cuenta que agrega directorios de forma recursiva, así quegit add .agregará todo lo que ha cambiado. -
Llama a
git commitpara crear el objeto de confirmación. El nuevo commit object tendrá el HEAD actual como su principal (después de que se complete el commit, el HEAD apuntará al nuevo commit object).
Digamos que creas tres commits de esta manera... Tu repositorio se verá así:
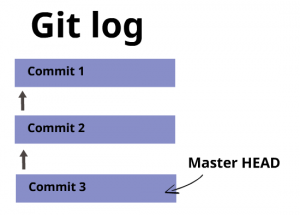
Otros comandos que son útiles en este punto:
git logmuestra un registro de todos los commits desde HEAD hasta el commit inicial. Puede hacer más que eso, por supuesto.git statusmuestra qué archivos han cambiado entre el estado actual del proyecto y el HEAD. Los archivos se clasifican en una de las tres categorías: (1) Archivos nuevos que no se han agregado (con git add), (2) Archivos modificados que no se han agregado y (3) Archivos que se han agregado.git diffmuestra la diferencia entre el HEAD y el estado actual del proyecto. Con la opción --cached, compara archivos agregados contra HEAD; de lo contrario, compara los archivos que aún no se han agregado.git mvygit rmmarcan los archivos para ser movidos (renombrados) y eliminados, respectivamente, de forma muy similar agit add.
Mi flujo de trabajo personal generalmente tiene este aspecto: primero hago algo de programación y luego termino de actualizar algunos archivos y luego ejecuto los siguientes comandos:
1git status # para ver qué archivos he cambiado. 2git diff [archivo] # para ver exactamente lo que modifiqué. 3git commit -a -m [mensaje] # para hacer commit.
Refiriéndose a un Commit
Ahora que has creado commits, ¿cómo se hace referencia a un commit específico? GIT proporciona muchas maneras de hacerlo. Aquí hay algunas:
- Por su nombre SHA1 (que puedes obtener de
git log). - Por los primeros caracteres de su nombre SHA1.
- Por un head. Por ejemplo,
HEADse refiere al commit object al que hace referencia HEAD. También se puede utilizar el nombre (como master). - Relativo a un commit. Colocando el símbolo de intercalación (^) después del nombre del commit devuelve al padre de ese commit. Por ejemplo, HEAD^ es el padre del actual head commit.
Creando una Rama
Para crear una rama, digamos que tu repositorio se ve así:
Vamos a saltar al commit (2) e iniciar un nuevo trabajo desde allí. Primero deberás saber cómo hacer referencia al commit. Puedes usar git log para obtener el nombre SHA1 de (2):
1$ git log 2commit df73f34fac344778e1f5a836fb88a897e0b8d491 3Author: Alejandro Sanchez <a@stcsolutions.com.ve> 4Date: Wed Mar 8 13:18:37 2017 -0500
En mi caso, el conjunto alfanumérico del nombre SHA1 de la rama es: df73f34fac344778e1f5a836fb88a897e0b8d491
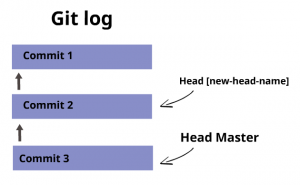
Ahora, podemos usar el comando git branch para iniciar una nueva rama desde ese commit en particular en:
1git branch [new-head-name] df73f34fac344778e1f5a836fb88a897e0b8d491
Este comando creará un nuevo head con el nombre dado y apuntará ese head al commit object solicitado. Si se omite el commit object, apuntará a HEAD.
Ahora nuestro árbol de commit se ve así:
Cambiando Entre Ramas
Para comenzar a trabajar en esa nueva rama, debes establecer el head actual en el head que acabamos de crear. Esto se hace con git checkout:
1git checkout [head-name]
Este comando hace lo siguiente:
- Apunta al HEAD del commit object especificado por [head-name].
- Vuelve a escribir todos los archivos en el directorio para que coincidan con los archivos almacenados en la nueva HEAD commit.
☝ Nota importante: Si hay cambios sin haber hecho commit al ejecutar git checkout, GIT se comportará de manera muy extraña. La extrañeza es predecible y a veces útil, pero es mejor evitarla. Todo lo que tienes que hacer, por supuesto, es confirmar todos los cambios nuevos antes de revisar el nuevo head.
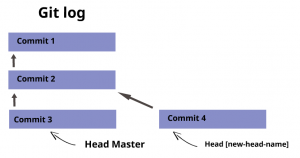
Después de hacer checkout en el [new-head], fijarás los head. Ahora puedes agregar los cambios y realizar commit como se indica arriba. El repositorio resultante se ve así:
Fusionando
Una vez que hayas terminado de implementar una nueva fusión en una rama, querrás traer esa nueva fusión a la rama principal, para que todos puedan usarla. Puedes hacerlo con el comando git merge o git pull.
La sintaxis del comando es la siguiente:
1git merge [head] 2git pull . [head]
Estos comandos realizan las siguientes operaciones: deja que el head actual se llame current, y que el head que se va a fusionar se llame merge.
- Identifica el ancestro común de current y merge. Llámalo ancestor-commit.
- Tratar con los casos fáciles. Si el ancestor-commit es igual a merge, entonces no hagas nada. Si el ancestor-commit es igual al actual, entonces haz un adelanto del merge.
- De lo contrario, determina los cambios entre ancestor-commit y merge
- Intenta fusionar esos cambios dentro de los archivos en current.
- Si no hubo conflictos, crea un nuevo commit con dos padres: current y merge. Establece current (y HEAD) para que apunte a este nuevo commit, y actualiza acordemente los archivos de trabajo para el proyecto.
- Si hubo un conflicto, inserta apropiadamente los marcadores de conflicto e informa al usuario. Ningún commit es creado.
☝ GIT puede ser muy confuso si hay cambios sin commit en los archivos cuando le pides que realice una fusión o merge. Por lo tanto, asegúrate de hacer commit a los cambios que hayas realizado hasta ahora antes de fusionar.
Resolviendo conflictos
Surge un conflicto si el commit a fusionar tiene un cambio en un lugar específico, y el commit actual tiene un cambio en el mismo lugar específico. GIT no tiene manera de decir qué cambio debe tener prioridad.
Para resolver el commit, edita los archivos para corregir los cambios en conflicto. Luego ejecuta git add para agregar los archivos resueltos. A continuación, ejecuta git commit para confirmar la fusión reparada. GIT recuerda que estabas en medio de una fusión, por lo que establece correctamente los padres del commit.
Colaboración GIT
GIT puede funcionar sin necesidad de conectarse a un servidor externo porque todos los archivos git se encuentran dentro de la carpeta .git.
Sin embargo, esto significa que, para manipular el repositorio, también necesitas tener acceso a los archivos de trabajo. Esto se traduce en que dos desarrolladores de GIT no pueden, de forma predeterminada, compartir un repositorio.
Para compartir el trabajo entre los desarrolladores, GIT utiliza un modelo distribuido de control de versiones. No asume ningún repositorio central. Es posible, por supuesto, usar un repositorio como el "central", pero es importante entender primero el modelo distribuido.
Control de Versiones Distribuido
Digamos que tú y tu amigo quieren trabajar en el mismo proyecto. Tu amigo ya ha hecho algún trabajo en ello. Hay tres tareas que debes realizar para descubrir cómo hacerlo:
- Obtén una copia del repositorio actualizado de tu amigo (git clone).
- Obtén los cambios que realiza tu amigo en su propio repositorio (git pull).
- Hazle saber a tu amigo sobre los cambios que hiciste (git push).
Especificación remota
GIT proporciona una serie de protocolos de transporte para compartir información del repositorio, como SSH y HTTP. Estaremos utilizando HTTP mayormente, ya que SSH es para usuarios más avanzados y requiere de configuración extra.
Para comenzar a trabajar en colaboración con proyectos remotos, necesitaremos conocer la URL remota del proyecto. Al usar HTTP, el remoto se verá así:
1https://github.com/<github-username>/repository-name.git
Github.com
Por ejemplo, cuando usas un repositorio de github.com, puedes encontrar el remoto en la página de inicio del repositorio:
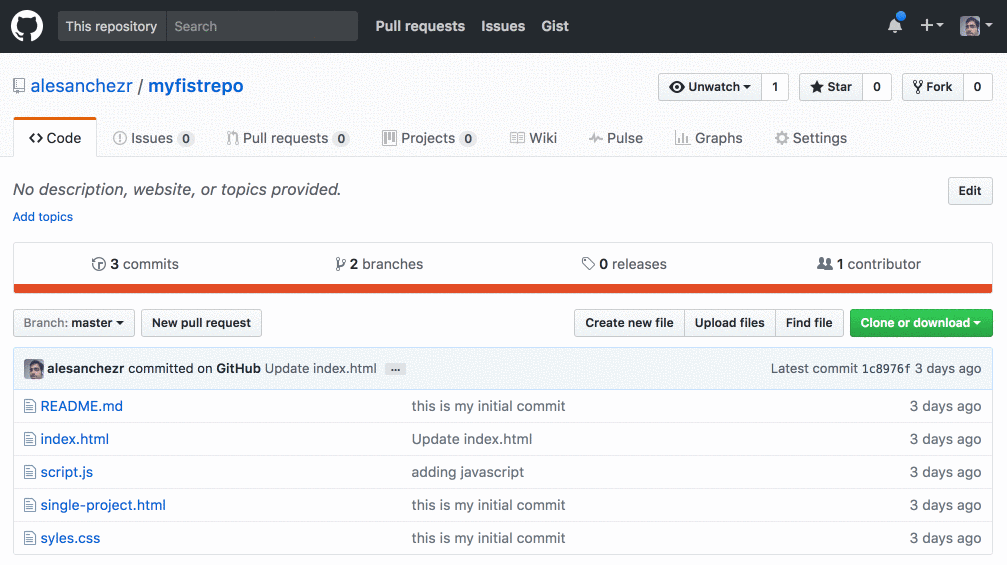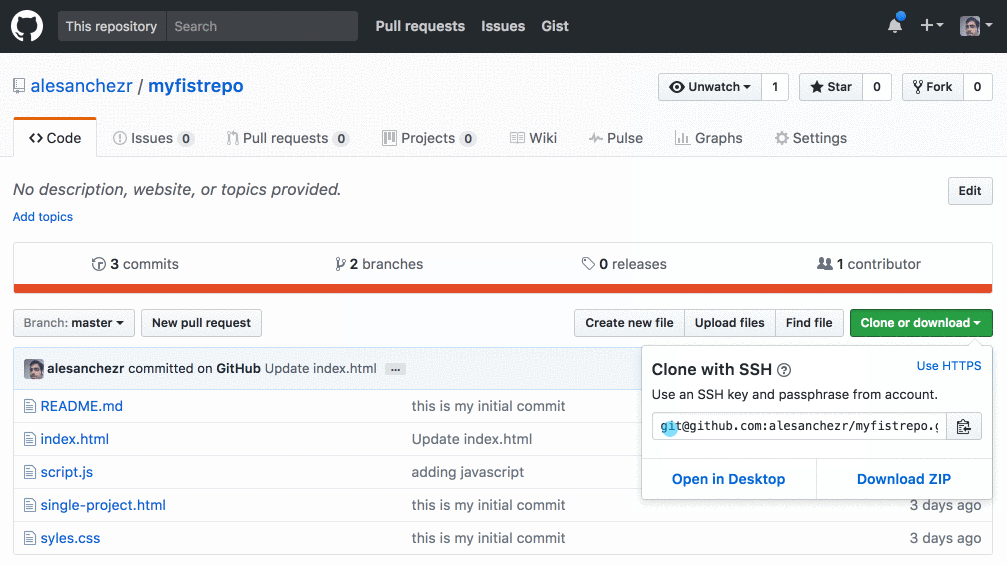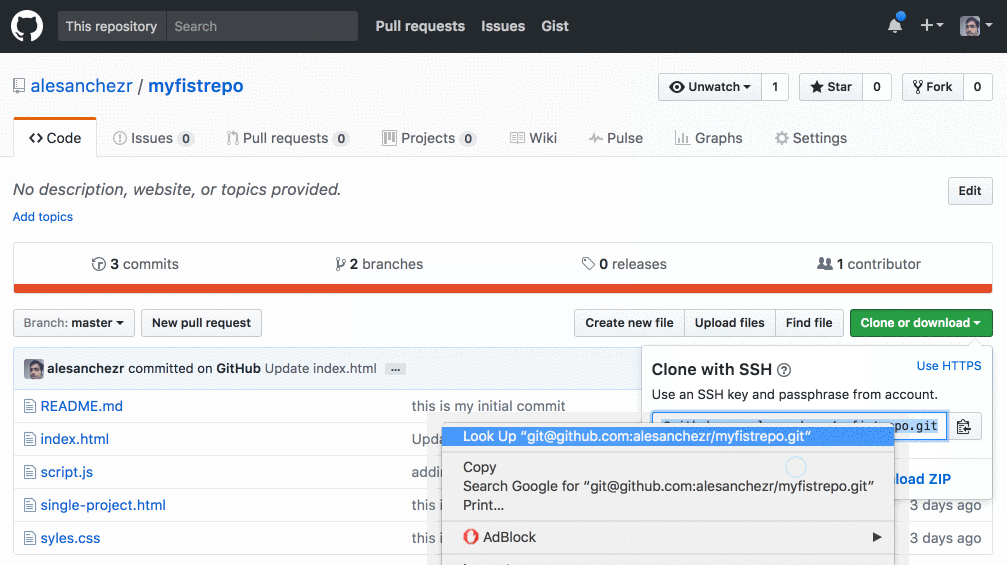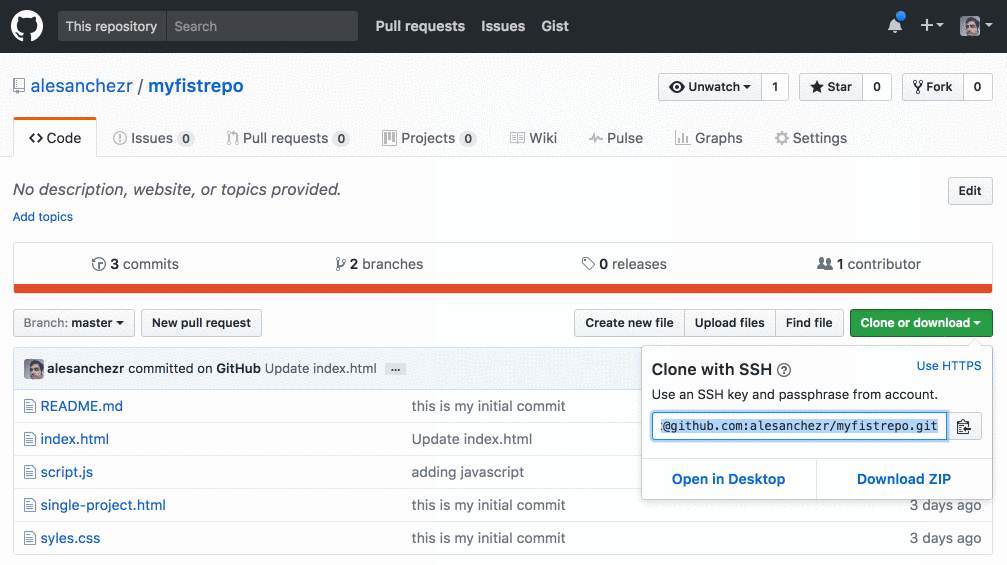
Añadiendo un Control Remoto
Si estás trabajando en un repositorio local y deseas conectarlo a un repositorio remoto, puedes agregar un remoto. Primero, busca la URL remota en el repositorio remoto.
Una vez que conozcas la URL remota, puedes agregarla a tu proyecto. Debes elegir un alias para el control remoto; de forma predeterminada, usamos normalmente origin. Agrega el control remoto ejecutando el siguiente comando:
⚠️ En nuestras plantillas ya tendrás una configuración de origin desde el repositorio de dicha plantilla. En esos casos, no debes eliminar el origin original, sino que necesitarás usar otro término (por ejemplo, new o new-origin, etc.) para agregar su nuevo control remoto.
Agrega el control remoto ejecutando el siguiente comando:
1git remote add origin [remote-url] 2# para asegurarnos de que el control remoto se haya configurado correctamente, podemos obtener el valor de la url 3git remote get-url origin
Pushing (subiendo) al Remoto
Digamos que tienes una rama en tu repositorio local llamada "nueva-rama". Esa rama se puede subir haciendo lo siguiente:
1git push origin [nueva-rama]
Si otra persona también ha subido algunos cambios a esa rama, GIT rechazará el push y te dirá que primero descargues esos cambios en tu repositorio local antes de continuar.
Deberás:
- Descargar los archivos.
- Combinarlos en tu código.
- Resolver cualquier conflicto que pueda haber aparecido.
Después de resolver el o los conflictos, puedes seguir adelante e intentar git push nuevamente.
Pulling (descargando) del Remoto
Digamos que hay una rama en el repositorio remoto llamada "desarrollo". Puedes descargar esta rama en tu propio repositorio ejecutando el siguiente comando:
1git pull origin desarrollo
El comando git pull intentará fusionar todos los archivos entrantes en tu rama local. Si encuentra algún conflicto en el código, te dará un error y te pedirá que resuelva esos conflictos.
Después de solucionar los conflictos, puedes usar git add en los archivos y git commit para mantener una copia limpia y sin errores de tu código en el repositorio.
Clonando el Repositorio (git clone)
Para hacer una copia de un repositorio remoto para tu propio uso, ejecuta git clone [especificacion-remota].
Por ejemplo, si el repositorio remoto se encuentra en git@github.com:alesanchezr/myfirstrepo.git, ejecutarías:
1git clone git@github.com:alesanchezr/myfirstrepo.git
Esto haría lo siguiente:
- Crear un directorio
myfirstrepoe inicializar un repositorio en él. - Copiar todos los commit objects del proyecto en el nuevo repositorio.
- Agregar un repositorio remoto denominado
originreferente al nuevo repositorio, y asociar origin congit@github.com:alesanchezr/myfirstrepo.gitcomo se describe a continuación. (Así como master, origin es un nombre predeterminado usado por Git). - Agregar heads remotos llamadas
origin/[head-name]que corresponden a los heads en el repositorio remoto. - Configurar una head en el repositorio para rastrear el head
origin/[current-head-name]correspondiente, es decir, el que estaba actualmente activo en el repositorio que se está clonando.
Una referencia del repositorio remoto es un alias que GIT usa para referirse al repositorio remoto. Generalmente será origin. Entre otras cosas, GIT asocia internamente la especificación-remota con la referencia del repositorio remoto, por lo que nunca más necesitarás volver al repositorio original.
A partir de ahora, podrás decir origin en lugar de git@github.com:alesanchezr/myfirstrepo.git.
Una rama que rastrea una rama remota conserva una referencia interna a la rama remota. Esta es una comodidad que le permite evitar escribir el nombre de la rama remota en muchas situaciones.
Lo importante a tener en cuenta es que ahora tienes una copia completa del repositorio completo de tu amigo. Cuando se ramifica, confirma (commit), fusiona u opera de otra manera en el repositorio, operas solo en tu propio repositorio. GIT solo interactúa con el repositorio de tu amigo cuando le pidas específicamente que lo haga.
🔗 Aquí hay una lista de otros excelentes recursos para aprender GIT: http://sixrevisions.com/resources/git-tutorials-beginners/
Especialmente deberías probar estos dos:
• https://try.github.io
• http://learngitbranching.js.org/