Beautiful Soup
Python
Web Scraping With Beautiful Soup
Web Scraping¶
Web Scraping is known as one of the most important methods to retrieve content and data from a website automatically using software. This information can later be used to add content to a database, export information to structured document types, and so on.
The list of things we can scrape on the web is extensive, but includes:
- Social networks (Facebook, Twitter...).
- Search engines (Google, Bing...).
- Corporate pages: online stores, services, business information, etc...
- Official government and news sites.
There are two ways of scraping, depending on what we want to obtain from the Internet:
- Obtain files/documents.
- Obtaining information.
The difference between the first and second point is that a file contains information but is not described on the web page. With the second point, what we are looking for is to extract paragraphs, titles, quantities, amounts, etc. immersed in the web.
As it is evident, we will use Python to obtain content from the Internet. Keeping the use of the same language ensures that the whole ETL (Extract, Transform, Load) process is integrated, increasing readability and maintainability.
1. Get files/documents¶
In Python, the requests package allows interacting with HTTP URIs and makes it possible, for example, to download resources and files hosted in some web page. The function that allows us to do this is get and, in our case, it would allow us to download some information and transform it, for example, into a Pandas DataFrame.
Step 1. Find the resource to download¶
In this case, we are interested in downloading information about income in the United States. To do so, since we do not have any information in our database (it is empty), we search for resources on the Internet. We locate a source that could allow us to develop a predictive model, and we access it:
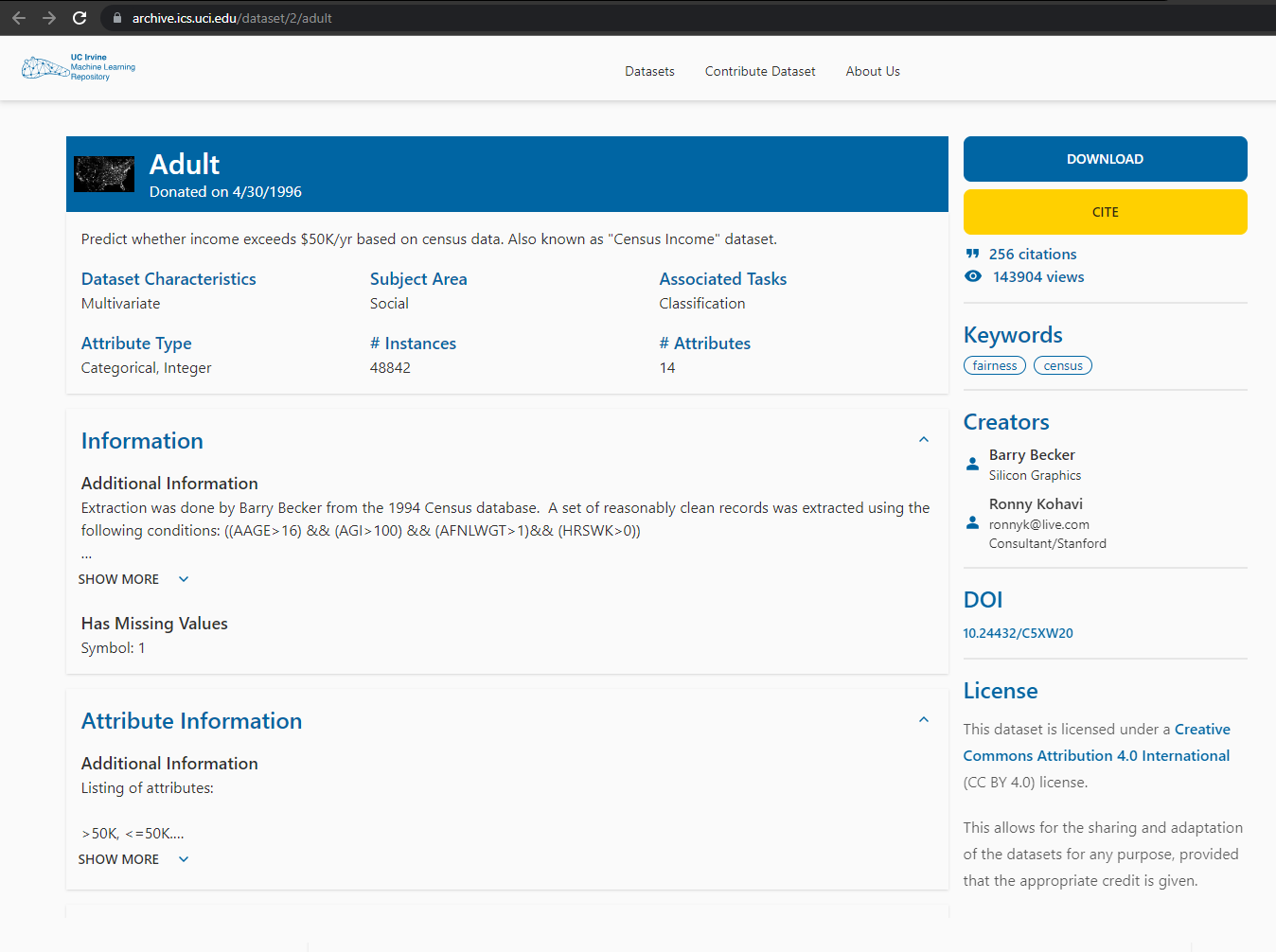
Step 2. Locate the resource download point¶
The next step is to figure out from which address we can download the resource. The UCI Repository provides a very intuitive interface for downloading resources. By copying the address from the Download button, we can easily obtain the download point. However, depending on the web page, sometimes getting this link is the most complicated part of the whole process.
After analyzing the website, we obtain that the download link is as follows: https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data.
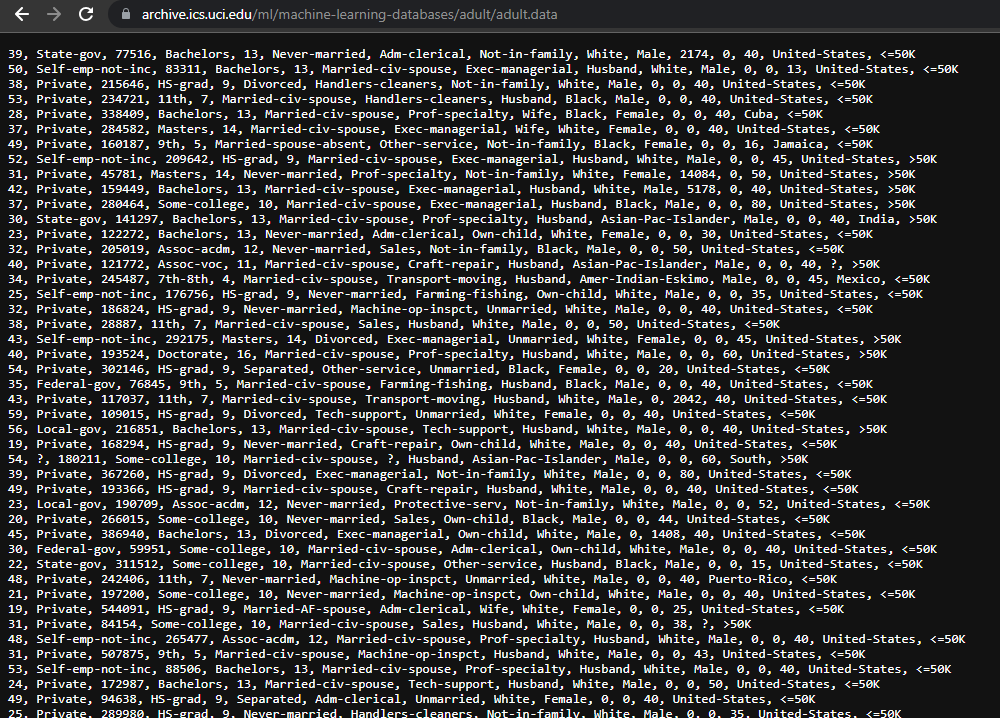
Step 3. Schedule the download of the file¶
The last thing that remains before being able to work with the information is to download it. To do this, we will use the requests package, as it provides a very simple mechanism to use:
import requests
# Select the resource to download
resource_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
# Request to download the file from the Internet
response = requests.get(resource_url)
# If the request was executed correctly (code 200), then the file could be downloaded
if response:
# The file is stored in the current directory for later use
with open("adult.csv", "wb") as dataset:
dataset.write(response.content)
The result is a file that is fully usable in our directory and that comes from the Internet, fully usable for the rest of the steps to be performed to train our Machine Learning model.
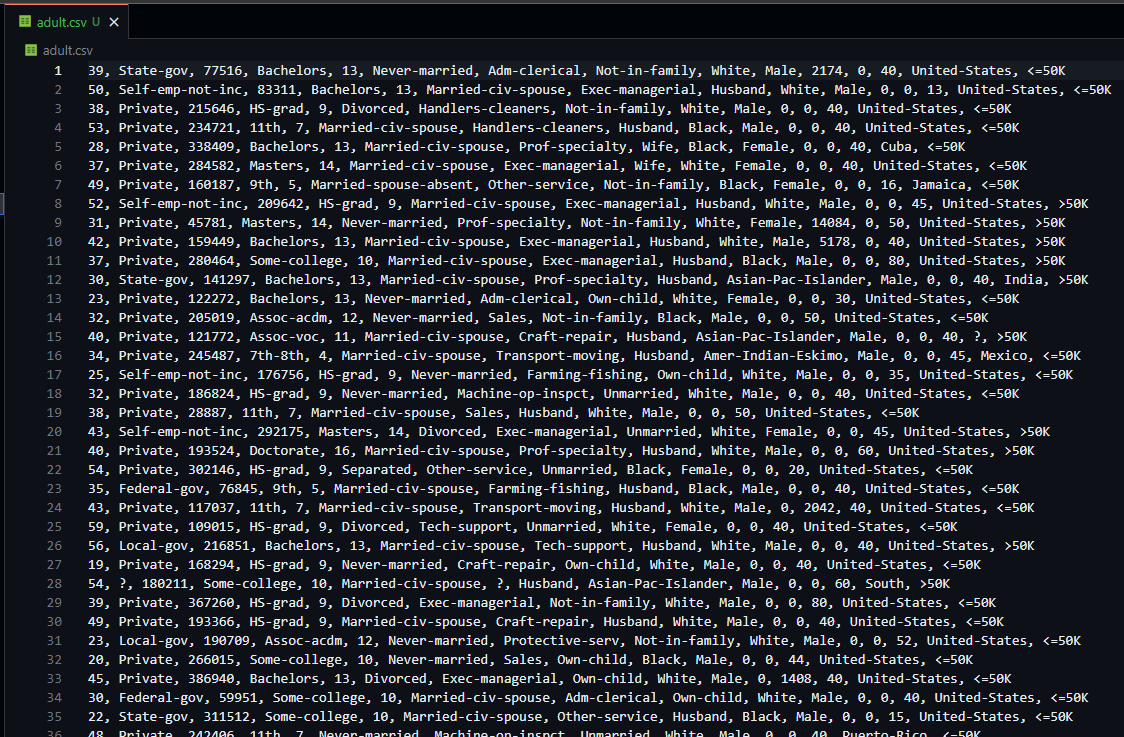
Now, we could read it with Pandas and create a DataFrame from the file.
2. Obtaining information¶
Getting information is a more tedious process than the previous one, because we need to go deep into the HTML structure of the documents to get that information. There are many ways to carry out this process, as well as many Python tools and packages that enable us to do it. requests and BeautifulSoup are a good combination to carry out this task successfully and in the simplest way.
Step 1. Find the content to obtain¶
In this case, we are interested in obtaining information about the cheapest apartment that can be purchased in Guardamar del Segura, a coastal town south of Alicante. Since we have no information about it, we decided to look for it in a real estate portal such as Inmobiliaria CGI. The first step is to access the website, filter by city and sort the results on the web:
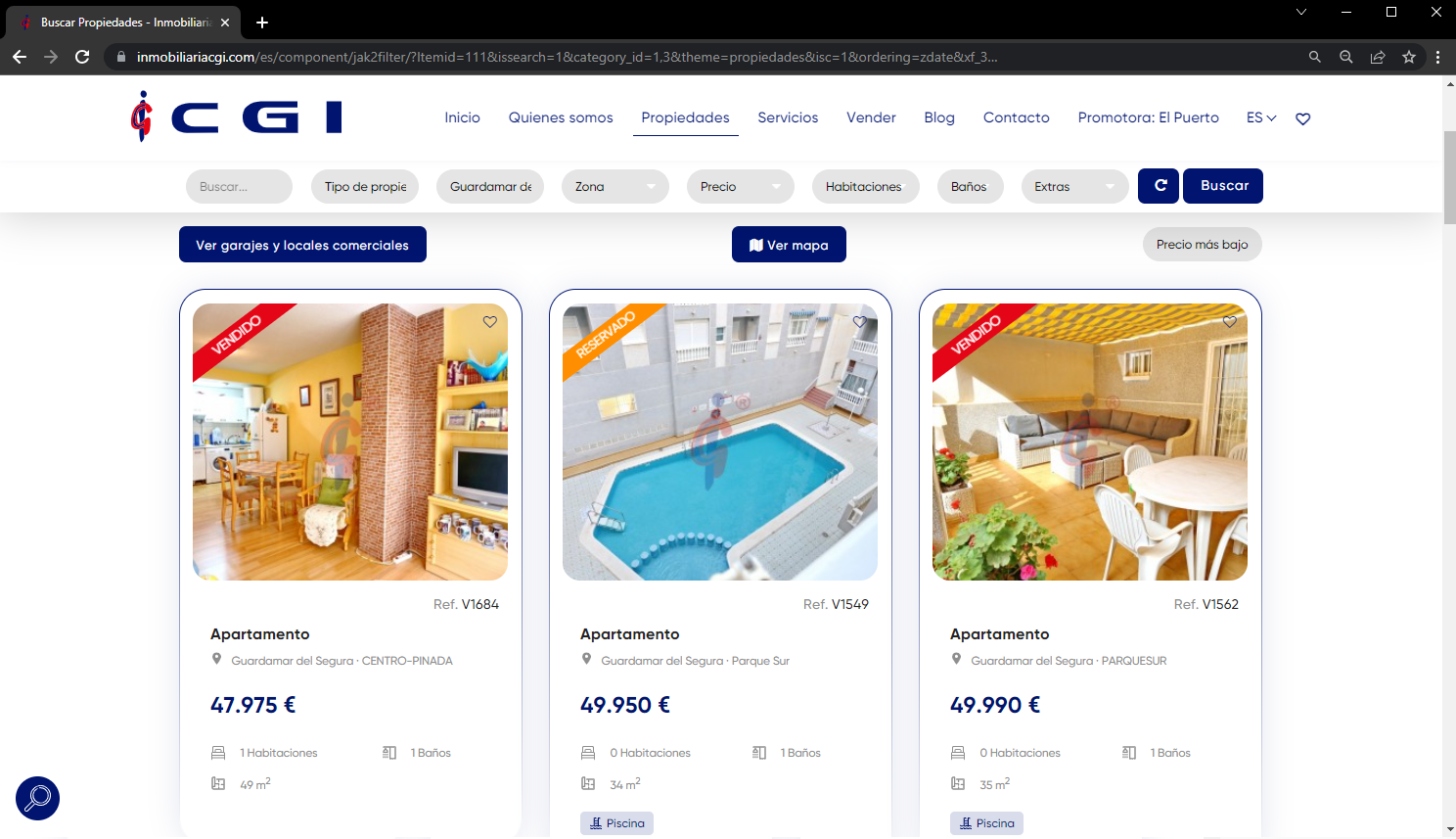
After filtering the content and preparing it (this is done with a simple example, but normally results are filtered and sorted at code level), we obtain the URL of the general content, on which we will obtain the total amount: https://inmobiliariacgi.com/es/component/jak2filter/?Itemid=111&issearch=1&category_id=1,3&theme=propiedades&isc=1&ordering=zdate&xf_3=2&orders[xf5]=xf5
Step 2. Download all the HTML content of the URL¶
Next, we must download the content of the previous page. To do this, we use the requests library to download the HTML in plain text format, and BeautifulSoup to generate the tree of elements and be able to perform queries to obtain the information we want to get.
import requests
import time
from bs4 import BeautifulSoup
# Select the resource to download
resource_url = "https://inmobiliariacgi.com/es/component/jak2filter/?Itemid=111&issearch=1&category_id=1,3&theme=propiedades&isc=1&ordering=zdate&xf_3=2&orders[xf5]=xf5"
# Request to download the file from the Internet
response = requests.get(resource_url, time.sleep(10))
# If the request has been executed correctly (code 200), then the HTML content of the page has been downloaded
if response:
# We transform the flat HTML into real HTML (structured and nested, tree-like)
soup = BeautifulSoup(response.text, 'html')
soup
As you can see, the soup object contains the HTML and from it you can make certain queries to obtain the information. In this case we are looking for the amount (marked in red in the image). In order to perform a successful extraction, we must find the element in the HTML of the web page before starting to work with the soup object. To do this, we use the developer tools of our browser:
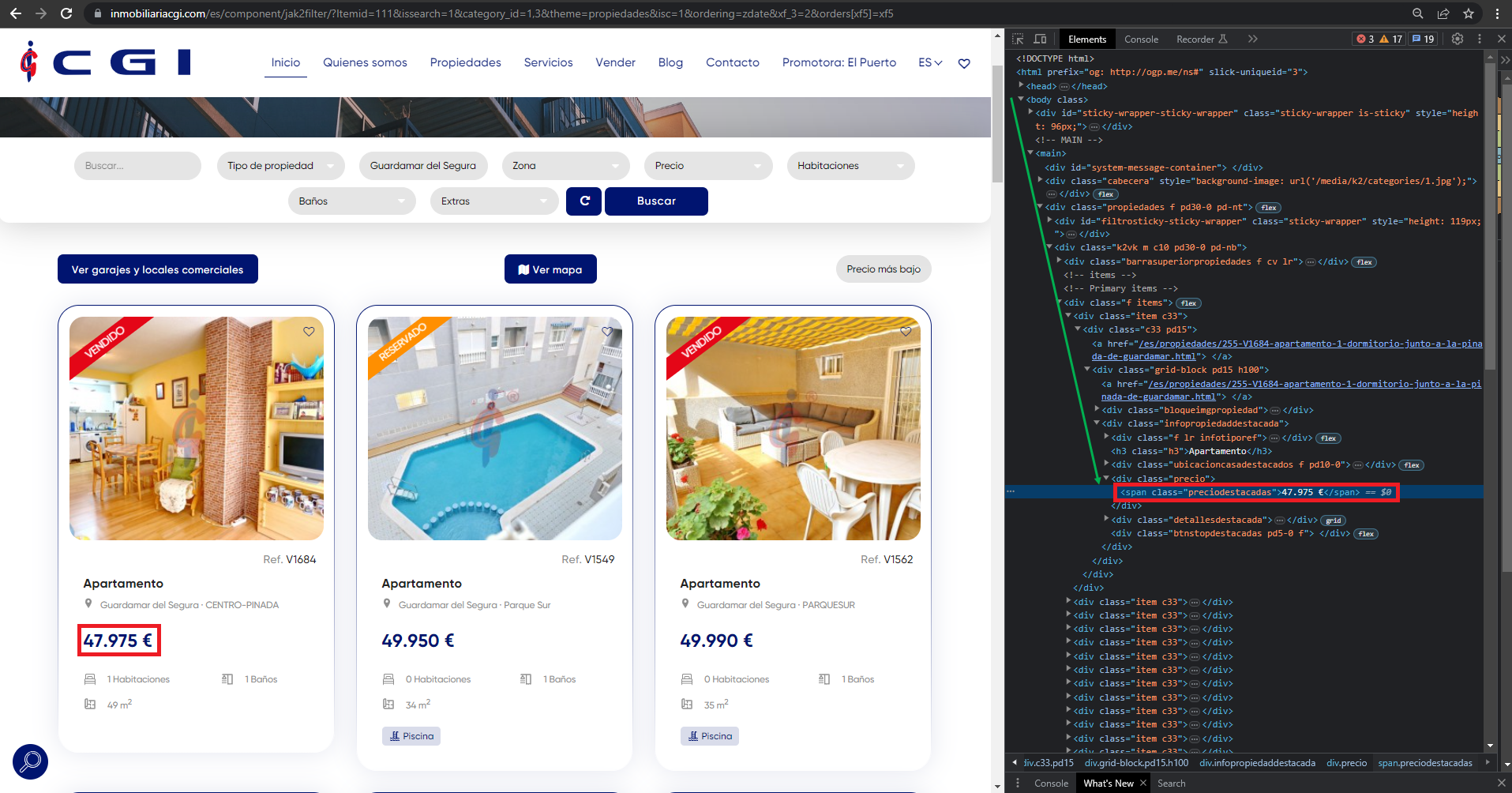
Searching for the element, we find it enclosed within the following div:
<div class="precio">
<span class="preciodestacadas">47.975 €</span>
</div>
In addition, as shown in the green arrow, this previous element is enclosed within a hierarchy that triggers the body element of the HTML. There are three ways to extract the value we want:
- Filter by hierarchy.
- Filter by tag name.
- Filter by attributes.
Filter by hierarchy¶
This type of filter requires going through the whole hierarchical tree of the HTML until finding the element. We know that after finding the element and observing the previous image, the hierarchy is as follows:
body > main > div > div > div > div > div > div > div > div > span
And the span element contains the amount we want to extract. However, this way of extracting information is very inefficient, it is not maintainable (small changes in the web page can greatly affect the extraction) and requires very high development times, since there are web pages that have an even more complex hierarchy.
Filter by tag name¶
This is one of the most common and widely used filters. It is the most basic filter since it consists of passing the name of the tag to search in the search function, and then selecting the desired one.
In our example, we are looking for a span element, so we just have to find all the ones in the HTML document and process them until we find the desired one.
import re
# Get all elements of type 'span' from HTML document
spans = soup.find_all("span")
# We iterate through each of the results to find the element that contains the given amount. Since the amount we are looking for is the first of all, we search for it (for example, with a regular expression) and when we find it, we print its value
for span in spans:
amount = re.search(r'\d+\.\d+', span.text)
if amount:
break
print(f"The price of the cheapest house in Guardamar del Segura is {amount}")
However, this methodology is not very useful if, for example, there is another amount on top that is not related to what we want to extract. In addition, it is not very time efficient since it requires that all the elements of the web be analyzed until the appropriate one is found. This makes it a poor alternative for real-time environments, large analyses, and so on.
Filter by attributes¶
We can use another mechanism to select elements from our HTML tree: identifiers and classes. In this way, we can quickly locate the element through its class. So, if the div that contained the span was the following:
<div class="precio">
<span class="preciodestacadas">47.975 €</span>
</div>
Then, using the class name preciodestacadas we could quickly filter this element and get it.
amounts = soup.find_all("span", class_="preciodestacadas")
print(f"The price of the cheapest house in Guardamar del Segura is {amounts[0].text}")
To get the text of a span element, we must use the text attribute, as shown in the code above.